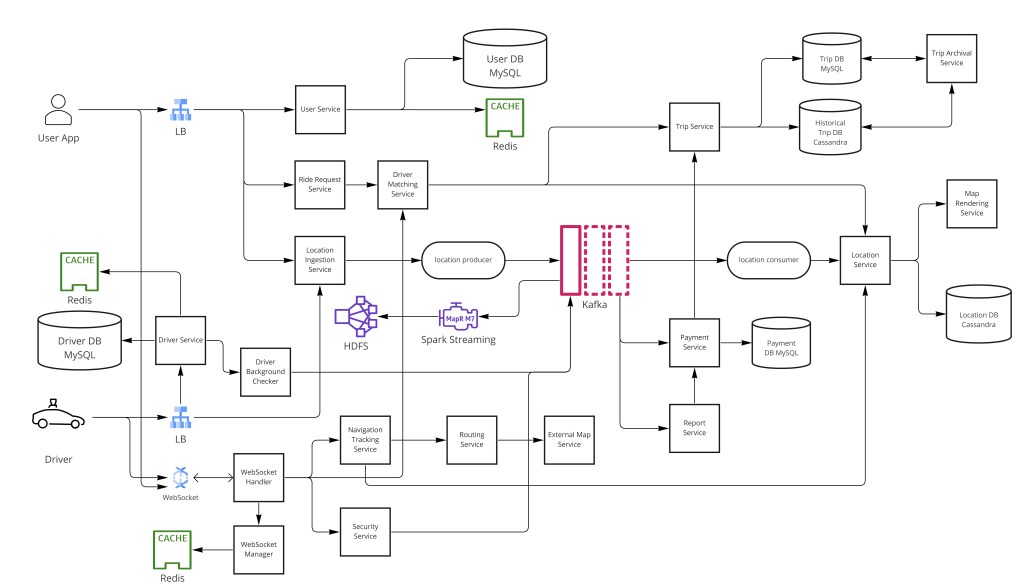
像 Uber 或 Lyft 这样的打车平台是一个实时双边市场:它必须持续摄取数百万司机的 GPS 流、以低延迟把乘客匹配给司机,并处理跨全球机群的金融交易——全都在 1.5 亿月活和每天 1500 万次行程下。"叫一辆车"这个看似简单的动作隐藏一个艰巨的分布式系统问题:你需要一个能处理数百万并发移动对象的近实时地理空间索引、一个全局优化而非贪心的匹配算法、一个行程生命周期的可靠状态机、在数秒内响应供需失衡的动态定价,以及一个财务正确而又不拖慢预订体验的支付管道。
- GPS 管道 = 至多一次——丢一个 5 秒包可忽略;对位置数据,保证投递的开销不值得。
- 内存索引 + Cassandra——内存空间索引做亚毫秒匹配查找;Cassandra 做持久位置历史,按城市和产品类型分区。
- 二分图匹配——批量进来的请求并全局求解最小平均接驾时间,而非每请求贪心最近司机。
- Geohash / S2 cell 做地理索引——把 lat/lng 编码成分层 cell;在正确精度级别查 cell 来查附近司机。
- 一致性哈希(Ringpop)——把司机位置数据均匀分布在节点上,自动重分区。
- 行程状态机——显式状态(REQUESTED → ACCEPTED → EN_ROUTE → IN_TRIP → COMPLETED)防止非法转换并使重试安全。
- 经供需比的动态定价——每 60–120 s 按 geohash cell 计算;乘数上限防止 PR 灾难。
- 异步支付——支付扣款和司机付款在行程完成关键路径之外,以避免处理延迟降低预订体验。
GPS 包每 ~5s 流入一个消息队列(至多一次投递)。一个由 Cassandra 支撑的内存空间索引存司机位置,按城市和产品类型分区。匹配用批量二分图优化——而非贪心最近司机——以最小化全局平均接驾时间。Geohash 或 Google S2 cell 支持 O(1) 半径查询。行程是一个显式状态机。动态定价是按 geohash cell 计算的比率。支付经第三方支付处理器异步处理。
第 1 步 — 澄清需求
深入前显式界定问题。打车很宽——精确定义你会和不会设计什么。
功能需求
- 在地图上实时显示可用司机位置。
- 乘客请求一次行程——系统把他们匹配给附近可用司机。
- 预订前显示 ETA 和预先价格估计。
- 行程中实时位置跟踪(乘客看司机移动)。
- 行程完成:费用计算、支付、收据。
- 司机收入仪表盘和行程历史。
- 带背景调查的司机入驻。
非功能需求
- 低延迟——司机位置更新 ~5 s 内可见;匹配响应 2 s 内。
- 高可用——即便部分失败市场也必须可达;匹配服务宕意味零收入。
- 一致性——一个司机不能被双重匹配;一次行程必须恰好有一个司机。
- 全球规模——1.5 亿月活、每天 1500 万次行程、跨数百城市。
- 地理感知——查询本质是空间的;系统必须高效按位置索引和搜索。
显式陈述范围外:欺诈检测、司机激励计划、拼单分账、预约行程。这让你把面试时间聚焦在真正难的部分——GPS 管道、匹配和行程状态机。
第 2 步 — 容量估算
粗略数学锚定你的架构选择。假设 Uber 规模:1.5 亿月活、每天 1500 万次行程。
GPS 写负载
- 峰值活跃司机:假设傍晚高峰全球 1M 并发司机。
- 每个司机每 5 s 发一个 GPS 包 → 峰值 1M ÷ 5 = 200,000 位置写/秒。
- 每个包 ~100 字节(driver_id、lat、lng、timestamp、heading)→ ~20 MB/s GPS 摄取。
- 这是突发流——消息队列必备以吸收尖峰。
行程与匹配负载
- 15M 行程/天 ÷ 86,400 s ≈ ~174 行程/秒平均;峰值(周五 6 点)3–5× → ~700 行程请求/秒。
- 每个行程请求触发一次匹配计算、一次 ETA 查询和至少两次位置读(乘客 + 半径内司机)。
- 匹配是 CPU 受限的;为专用匹配服务实例规划,不与 GPS 摄取共享。
存储
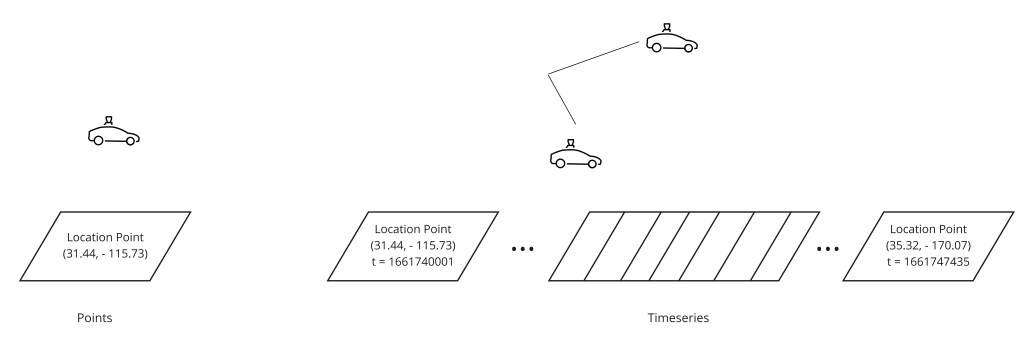
- GPS 历史:200K 写/秒 × 100 字节 × 86,400 s ≈ ~1.7 TB 原始位置数据每天。只有最后已知位置需在内存;历史去 Cassandra。
- 行程记录:15M 行程 × ~1 KB(行程元数据、费用、路线摘要)≈ ~15 GB/天,在 SQL 里完全可管理。
- 内存空间索引:1M 并发司机 × 每条 200 字节 ≈ ~200 MB——轻易装进单节点但为可用分片。
GPS 写负载(200K/s)是主导的数据平面关切。行程请求率(700/s)相对适中。你的架构必须处理前者而不让它饿死后者。
第 3 步 — API 设计
打车服务里的关键 REST 端点:
# 司机 — 位置更新(高频,至多一次)
POST /driver/location
{ driver_id, lat, lng, heading, timestamp }
# 乘客 — 请求一次行程
POST /trips
{ rider_id, pickup_lat, pickup_lng, dropoff_lat, dropoff_lng, product_type }
→ 返回 { trip_id, estimated_eta_s, estimated_fare, driver_info }
# 行程状态(轮询或 WebSocket 推送)
GET /trips/{trip_id}
→ { status, driver_location, eta_s, fare_cents }
# 司机 — 接受/拒绝一次匹配
POST /trips/{trip_id}/accept { driver_id }
POST /trips/{trip_id}/decline { driver_id }
# 司机 — 行程生命周期事件
POST /trips/{trip_id}/arrived # 司机在接驾点
POST /trips/{trip_id}/start # 行程开始
POST /trips/{trip_id}/complete # 行程结束,触发费用 + 支付POST /driver/location 端点以极高频率调用并用至多一次投递——服务器接受就继续;无确认重试。行程生命周期端点幂等——对一个已完成行程调 /complete 两次在状态机级别是 no-op。
第 4 步 — 司机和乘客注册
用户服务处理市场两侧的认证和资料管理。司机入驻涉及一个额外的背景检查器,在司机被激活前验证事故历史、驾照有效性、SSN 和车辆状态。频繁访问的用户资料缓存在 Redis 以减少高流量查找路径上的数据库负载。
司机资料携带超出乘客资料所需的额外状态:车辆细节(品牌、型号、车牌、颜色)、当前可用状态(OFFLINE / AVAILABLE / IN_TRIP),和产品类型资格(UberX、Comfort、Black、Pool)。这个资格存在 SQL 并缓存;匹配服务读它在跑分配算法前过滤司机池。
第 5 步 — GPS 摄取管道
每个活跃司机大约每 5 秒传输一个 GPS 包,含他们的 user_id、当前位置和一个时间戳。每天 1500 万次行程、假设峰值 ~1M 并发活跃司机,这产生 ~200,000 写/秒——一个高量、突发的写流,同步 HTTP 端点无法吸收而不成瓶颈。
一个消息队列(Kafka 或专建的低延迟替代)把 GPS 生产者与位置处理消费者解耦,吸收 QPS 变化。司机写到队列而不等确认;消费者——位置更新 worker——排干队列并异步更新内存空间索引和 Cassandra。
投递保证是至多一次。单个丢失的 GPS 包可接受,因为下一个 5 秒后到达——保证投递的成本(重试循环、去重、更高延迟)为可忽略的好处增加复杂度。与支付的对比有教益:支付事件用至少一次,因为丢失支付消息有真实金融后果。
GPS 数据预处理
原始 GPS 读数有噪声——消费级传感器有 3–5 m 精度,卫星偶尔产生疯狂错误的定位。更新空间索引前,位置 worker 应用:
- 离群剔除——丢弃暗示不可能速度(如两个连续包间 >200 km/h)的读数。
- 地图匹配(map matching)——经地图服务 API 把 lat/lng 吸附到最近道路段,使司机图标出现在路上而非浮在建筑内 10 m。
- 卡尔曼滤波(可选,更高保真)——用卡尔曼滤波平滑 GPS 轨迹以减少乘客实时跟踪地图上的抖动。
WebSocket 维护持久连接——对把数据推给客户端很好,但来自司机应用的 1M 持久入站连接会在单个网关上饱和连接表内存。GPS 写模式(每 5 s fire-and-forget)更适合负载均衡器能分散到无状态摄取 worker 的短 HTTP POST。
第 6 步 — 地理空间索引
核心空间操作是:"给定一个在 (lat, lng) 的乘客,找半径 R 内所有可用司机。"在规模上高效做这个需要一个专建的地理空间索引,而非暴力扫描所有司机记录。
Geohash
Geohash 通过递归把世界二分成 2D 网格把一个 (lat, lng) 对编码成一个短字母数字字符串。每个额外字符把 cell 大小减半。一个 6 字符 geohash 表示一个 ~1.2 km × 0.6 km 的 cell。要找附近司机,你在适当精度查目标 cell 加 8 个相邻 cell——九次查找返回大约 1–2 km 内的所有候选。
-- Geohash 精度表
长度 cell 宽 cell 高 用例
4 ~39 km ~20 km 城市级
5 ~4.9 km ~4.9 km 街区
6 ~1.2 km ~0.61 km 街块级(司机搜索好用)
7 ~153 m ~153 m 细粒度 ETA
-- 找附近司机:查目标 cell + 8 个邻居
nearby_cells = geohash_neighbors(rider_geohash, precision=6)
-- 返回 9 个 cell;在内存索引查那些 cell 里 AVAILABLE 的司机Google S2 cell
Google S2 把球面映射到一个立方体,然后用希尔伯特曲线产生带优秀空间局部性的分层 cell ID。level 13 的 S2 cell 大约 1.3 km²,类似一个 6 字符 geohash。S2 是 Uber 内部用的(经他们的 H3 库,一个六边形变体);它比 geohash 更好处理极地畸变并支持高效的 cap/多边形查询。面试中任一可接受——geohash 更简单解释,S2/H3 更生产正确。
QuadTree
QuadTree 递归把 2D 平面细分成四个象限。含太多对象的节点被拆分。QuadTree 自然适应非均匀分布——密集城市核心得到细粒度,稀疏乡村保持粗糙。缺点是更新(一个司机在 cell 间移动)需要树重构,相比 geohash 的哈希查找方法昂贵。QuadTree 在游戏空间索引里比打车生产系统更常见,但带正确注意事项时是有效面试答案。
| 索引类型 | 强项 | 弱点 |
|---|---|---|
| Geohash | 简单字符串前缀查找;Redis 原生支持;易按前缀分片 | cell 边界伪影;高纬度非均匀 cell 形状 |
| Google S2 / H3 | 均匀 cell 面积;优秀空间局部性;多边形/cap 查询 | 更复杂的库;不广为理解 |
| QuadTree | 适应密度;分层聚合 | 昂贵更新;复杂树平衡;仅内存 |
| R-Tree (PostGIS) | 成熟 SQL 集成;原生处理多边形 | SQL DB 对 200K GPS 写/秒太慢;不适合热路径 |
第 7 步 — 位置存储架构
司机位置数据既需要匹配的高速查找,也需要行程历史的持久存储。这是两个不同的访问模式,需要两个不同存储层:
| 层 | 技术 | 用途 |
|---|---|---|
| 活跃索引 | 内存搜索索引 | 匹配期间实时司机查找的亚毫秒读写 |
| 持久存储 | Cassandra (NoSQL) | 持久行程和位置记录;横向可扩展的写 |
| 分区键 | DriverUUID + 时间桶 | 支持每司机高效的时间范围查询 |
| 分片 | 城市 / 分段 / 产品类型 | 按市场隔离负载;UberX、UberPool 等有不同供应池 |
| 分布 | 一致性哈希 (Ringpop) | 把数据均匀分布在 worker 节点;经 Airflow 自动重分区 |
内存索引按 geohash 前缀(或 S2 cell ID 前缀)分区。每个分片由一致性哈希决定的一组 worker 节点拥有——Uber 的 Ringpop 库实现这个环,允许加减节点而不重洗所有数据。当一个司机发位置更新,摄取 worker 哈希司机当前 geohash 找拥有分片,然后更新那个分片的内存 map。
持久层选 Cassandra,因为它以最终一致处理高写吞吐——正是 GPS 历史的画像。分区键是 (driver_id, date_hour_bucket),使一个司机一个时间窗里的所有位置记录共置一个节点,使"重建司机在行程 X 期间的路线"成为单分区读。
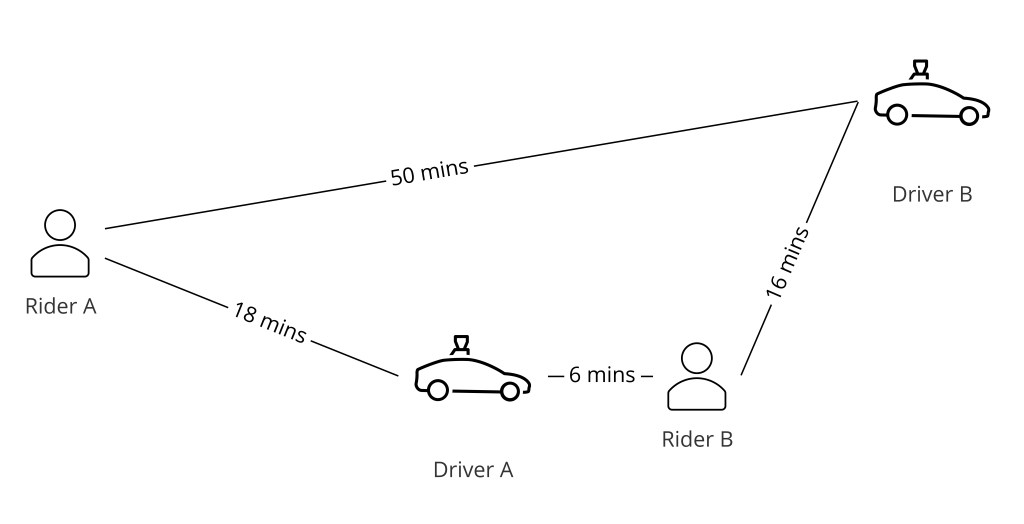
第 8 步 — 匹配算法
直觉方法——把每个进来的乘客请求分给最近可用司机——是贪心且全局次优的。若两个乘客靠近同一司机,贪心方法把司机给第一个请求者,可能让第二个乘客困在一个远得多的司机那里。
正确的框架是一个二分图匹配(bipartite graph matching)问题:乘客在一边,可用司机在另一边,边权代表接驾时间。系统在一个短窗口内批量进来的请求,并求解最小化整批所有乘客的全局平均接驾时间的分配——而不只是队列里第一个乘客。
-- 贪心(次优):
rider_A → 最近司机 D1 (2 分钟)
rider_B → 下一个司机 D2 (8 分钟)
平均接驾 = 5 分钟
-- 二分图匹配(最优):
rider_A → 司机 D2 (4 分钟)
rider_B → 司机 D1 (4 分钟)
平均接驾 = 4 分钟
-- 算法:匈牙利算法或最小费用流
-- 批窗口:通常 2–5 秒
-- 边权:来自路由 API 的 ETA(非欧氏距离)匹配管道细节
- 地理查找——在内存空间索引查乘客接驾点搜索半径(如 3 km)内所有
AVAILABLE司机。按产品类型(UberX、Comfort 等)过滤。 - ETA 评分——对每个候选司机,调路由服务(或用带道路因子的轻量直线估计)得一个真实接驾 ETA。在曼哈顿这样的网格密集城市,实际道路 ETA 显著胜过欧氏距离。
- 批量求解——收集当前批窗口里所有待处理乘客请求。用 ETA 作边权构建二分图。用匈牙利算法(O(n³))或大批的最小费用流近似求解。
- 派发邀约——给被分配的司机发一个匹配邀约。若司机在 ~15 s 内拒绝或不响应,乘客被重新排入下一批。反复拒绝的司机在未来批次被降优先级。
- 锁定司机——一旦司机接受,在空间索引里原子把他们的状态从
AVAILABLE翻到IN_TRIP以防止双重匹配。
一个 0.5 km 外但在河错误一侧的司机可能要 15 分钟;一个 1.5 km 外有清晰道路的司机要 3 分钟。用直线距离作边权在真实城市产生系统性错误的匹配。路由 API 调用昂贵——缓存频繁城市对或用预计算道路因子启发式做评分阶段,然后在找到匹配后用完整路由调用确认。
第 9 步 — 行程状态机
行程最好建模为一个显式状态机。每个状态转换由一个事件触发——来自司机或乘客应用,或来自内部超时——且必须幂等,使重放一个网络重试的事件不会错误推进状态。
REQUESTED
│ 找到匹配(二分图算法)
▼
DRIVER_ASSIGNED
│ 司机接受
▼
DRIVER_EN_ROUTE ← 司机驶向接驾
│ 司机到达
▼
DRIVER_ARRIVED ← 司机在接驾点等待
│ 乘客上车 / 司机点"开始"
▼
IN_TRIP ← 行程进行中
│ 司机在目的地点"完成"
▼
COMPLETED ← 费用算出,触发支付
从任何 COMPLETED 前状态:
REQUESTED / DRIVER_ASSIGNED → CANCELLED_BY_RIDER / NO_DRIVER_FOUND
DRIVER_EN_ROUTE / DRIVER_ARRIVED → CANCELLED_BY_DRIVER / CANCELLED_BY_RIDER把状态存在一个由应用级转换检查守卫的 SQL 行里防止非法跳转(如直接从 REQUESTED 到 IN_TRIP)。每个转换也发布一个事件到 Kafka,使下游服务——通知服务(发"司机将到"推送)、分析服务(记录事件)、支付服务(COMPLETED 时触发扣款)——能反应而不直接耦合到行程服务。
超时处理
- 若司机在被邀约 ~15 s 内不接受,行程服务把乘客重新排入并标司机为下一匹配周期降优先级。
- 若 ~2 分钟内 N 次重试后无司机找到,行程移到
NO_DRIVER_FOUND并通知乘客稍后再试。 - 一个分布式调度器(如 Celery beat 或一个简单的 Kafka 延迟消息)驱动这些超时转换而无需在热数据库上轮询循环。
第 10 步 — ETA 与路由
与其自建专有地图栈,打车平台与外部地图提供商(Google Maps、MapBox、OpenStreetMap)合作获道路图数据、路由和 ETA 计算。一个关键挑战是 GPS 坐标没有道路概念——原始纬度/经度必须经地图匹配吸附到最近道路段,然后才在屏上显示车辆图标或算 ETA。
ETA 计算层
- 道路图——一个加权有向图,节点是道路交叉口、边是带从历史速度数据和实时交通派生的行驶时间权重的道路段。
- Dijkstra / A*——道路图上的最短路径算法;A* 用一个地理启发式修剪搜索空间,实践中比 Dijkstra 跑得快。
- 交通调整——实时交通馈送(Google Traffic、HERE)持续调节边权;中午要 2 分钟的路下午 5 点可能要 12 分钟。
- ETA 缓存——热门城市对 ETA 以短 TTL(30–60 s)缓存,因为交通频繁变化。精确的每司机 ETA 新鲜计算但用缓存的道路图。
匹配服务为评分阶段用一个轻量 ETA 近似(直线距离 × 道路因子)以避免每批 N 次路由 API 调用。一旦匹配被确认,完整路由 API 计算显示给乘客的准确 ETA。
第 11 步 — 动态定价(Surge Pricing)
当一个地理区域需求超过供应,动态定价抬高费用以吸引更多司机到该区并减少价格敏感乘客的需求,重新平衡市场。实现动态定价是一个实时数据管道问题:
计算 surge 乘数
- 每 60–120 秒,定价服务从空间索引读:对每个精度 5–6(街区级)的 geohash cell,计数
pending_requests(等待的乘客)和available_drivers(AVAILABLE 状态)。 - 计算供需比:
ratio = pending_requests / max(available_drivers, 1)。 - 经查找表把比率映射到乘数(如 ratio < 0.5 → 1.0×;0.5–1.0 → 1.2×;1.0–2.0 → 1.5×;>2.0 → 2.0×)。给乘数设上限(如 3.0×)以避免紧急情况下的 PR 灾难。
- 把乘数写到每 geohash cell 一个 Redis key 带短 TTL(120 s)。所有定价查找命中 Redis,而非空间索引。
geohash cell 边界处会怎样?一个在高 surge cell 边缘的乘客可能离一个零 surge cell 几米。系统应聚合乘客 cell 加邻居的乘数并取加权平均,或简单用乘客的 cell。确切边界行为是产品策略决定——无论如何对乘客清晰披露 surge。
预先费用估计
乘客预订前显示的费用是基于:base_fare + (distance_km × per_km_rate + duration_min × per_min_rate) × surge_multiplier 的估计。最终费用用实际 GPS 跟踪的距离和时间。若实际费用显著超过估计(如司机绕路),乘客保护给超额设上限。
第 12 步 — 地图服务
地图服务提供三个关键功能:路由的道路图数据、ETA 计算,和应用 UI 显示的地图瓦片。打车平台与外部提供商合作而非自建——维护全球道路图(OpenStreetMap 编辑、交通数据合作、地图渲染管道)所需的投入巨大且不是核心竞争力。
关键集成点:
- 地理编码 / 反向地理编码——把人类可读地址("旧金山 Pier 39")转成 (lat, lng) 并反向。用于乘客应用的接驾/下车输入。
- Directions API——给定起点和终点,返回逐向导航和 ETA。每次确认匹配调一次以给司机显示其导航路线。
- 地图匹配 API——把原始 GPS 轨迹吸附到道路段。由 GPS 预处理管道和地图显示层调用以显示平滑司机图标。
- 地图瓦片——应用背景地图的栅格或矢量瓦片。经 CDN 从地图提供商服务;打车应用不重新托管瓦片。
第 13 步 — 数据模型
存在 SQL(行程记录、用户账户)和 Cassandra(位置历史)的关键表:
CREATE TABLE trips (
id BIGINT PRIMARY KEY,
rider_id BIGINT NOT NULL,
driver_id BIGINT,
status VARCHAR(32), -- REQUESTED|DRIVER_ASSIGNED|...
pickup_lat DECIMAL(9,6),
pickup_lng DECIMAL(9,6),
dropoff_lat DECIMAL(9,6),
dropoff_lng DECIMAL(9,6),
product_type VARCHAR(16), -- UBERX|COMFORT|BLACK|POOL
surge_multiplier DECIMAL(4,2),
estimated_fare_cents INT,
actual_fare_cents INT,
requested_at TIMESTAMP,
completed_at TIMESTAMP
);
CREATE TABLE drivers (
id BIGINT PRIMARY KEY,
availability VARCHAR(16), -- OFFLINE|AVAILABLE|IN_TRIP
product_types TEXT, -- 逗号分隔的可用类型
vehicle_plate VARCHAR(16),
rating DECIMAL(3,2),
last_lat DECIMAL(9,6),
last_lng DECIMAL(9,6),
last_geohash VARCHAR(12),
updated_at TIMESTAMP
);-- GPS 位置历史(写多,时序)
CREATE TABLE driver_location_history (
driver_id UUID,
time_bucket TEXT, -- 如 '2024-05-24-18'(每小时桶)
recorded_at TIMESTAMP,
lat DOUBLE,
lng DOUBLE,
heading SMALLINT,
PRIMARY KEY ((driver_id, time_bucket), recorded_at)
) WITH CLUSTERING ORDER BY (recorded_at DESC);
-- 分区 = 一个司机 × 一小时;查询 = "司机 D 在小时 H 的所有 GPS"第 14 步 — 支付处理
支付存在三个架构选项:
- 专有支付系统——完全控制,高建设成本和监管负担(PCI-DSS Level 1)。
- 直接第三方集成(PayPal、Block/Square)——更简单,但绑定一个提供商。
- 经处理器伙伴的无品牌支付网关——Uber 用 Braintree 的初始方法;支持多提供商灵活性和区域支付处理器支持而不暴露支付品牌。
支付扣款和司机付款计算异步处理以让它们远离行程完成关键路径。当一个行程到 COMPLETED,行程服务发布一个 TripCompleted 事件到 Kafka。支付服务消费这个事件、计算最终费用(实际距离 × 实际时长 × surge 乘数)、经处理器 API 扣乘客的已保存支付方式,并触发司机付款(通常每日批量结算而非每行程以减少转账费)。
支付幂等
支付服务在每次扣款调用时给支付处理器传一个唯一幂等键(如 trip_id + "charge")。若网络在扣款成功后、响应到达前掉线,用同键的重试在处理器是 no-op——乘客不被双重扣款。来自处理器的一个 webhook 确认成功或失败,这更新行程记录的支付状态。一个每晚对账作业抓住行程记录和处理器结算间的任何差异。
若 TripCompleted Kafka 事件被投递两次(至少一次语义)会怎样?支付服务必须按 trip_id 去重——若该行程已存在扣款记录,跳过扣款并返回已存在结果。这是幂等消费者模式:每个事件消费者必须处理重投而无副作用。
第 15 步 — 扩展与容错
一个全球打车平台必须挺过区域宕机、处理数百万并发连接,并在分布式服务机群间智能路由流量。
分片位置索引
内存空间索引按城市和产品类型分片——旧金山的 UberX 与伦敦的 Comfort 是完全独立的数据集。城市内,一致性哈希(Ringpop)把 geohash 前缀分布在 worker 节点上。一个司机在 geohash cell 间移动触发一次位置更新,哈希环自动把它路由到正确分片。当一个节点被加或移除,只有环上受影响弧上的键被重映射——相比朴素取模分区最小化数据移动。
多区域部署
每个主要都会区运行自己的匹配、GPS 摄取和空间索引集群——芝加哥的乘客从不需要伦敦的数据。跨区域通信限于用户资料读(激进缓存)和全局分析管道。这种地理隔离保持延迟低、故障爆炸半径小,并满足监管数据驻留要求。
熔断器与优雅降级
- 若路由 API(Google Maps)慢,匹配服务回退到欧氏距离估计。匹配略不准但仍派发。
- 若动态定价服务宕,回退到一个缓存乘数(或 1.0× 作安全默认)。行程继续;定价精度临时退化。
- 若 Cassandra 不可用,GPS 管道在 Kafka 缓冲并在存储恢复时追赶。只有历史记录被延迟——内存索引不受影响。
实时跟踪的 WebSocket
活跃行程期间,乘客应用实时显示司机位置移动。这需要一个推送通道,而非轮询——从数百万活跃行程每 1 s 轮询会为位置数据产生每秒数百万 HTTP 请求。解法:
- 一个 WebSocket 网关维护到活跃乘客和司机应用的持久连接。
- 当 GPS 管道处理一个当前在行程中的司机的位置更新,它把新位置发布到一个每行程 Pub/Sub 频道。
- WebSocket 网关订阅那个频道并把更新推到乘客的连接。
- 网关除连接表外无状态;它能在支持粘性会话(或像 Redis Pub/Sub 这样的分布式 pub/sub mesh)的负载均衡器后横向扩展。
第 16 步 — 关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| GPS 投递保证 | 至多一次 | 偶尔漏包;下一更新 5 s 内到达——影响可忽略 |
| 空间索引 | 内存 + geohash | 内存成本;须复制;不持久——但匹配速度至上 |
| 匹配算法 | 二分图批量求解 | 引入 2–5 s 批窗口延迟;相比贪心全局更好结果 |
| 位置持久化 | Cassandra(最终) | 历史最终一致——可接受;行程记录需正确性(SQL) |
| 支付 | 异步(Kafka + 处理器) | 行程后确认支付;罕见失败需对账作业抓住 |
| 地图服务 | 外部提供商 | 每 API 调用成本;依赖风险——但避免巨大的专有地图投入 |
| Surge 计算 | 周期批(60–120 s) | 乘数更新最多 2 分钟滞后;鉴于人类决策时间尺度可接受 |
打车设计被两个洞见主导:GPS 是高量时序流(至多一次,消息队列 + 内存 geohash 索引),且匹配是一个全局优化问题(二分图),而非每请求贪心查找。行程状态机保持生命周期转换正确且幂等。动态定价是每 geohash cell 的周期批计算。支付刻意异步以让它远离关键路径。其他一切——一致性哈希、Cassandra、多区域隔离——都从在每秒 200K GPS 写下处理那些约束而来。
为什么二分图匹配而非贪心最近司机?贪心独立地把每个乘客分给最近司机,这局部最优但全局次优——它能让附近乘客得到远得多的司机。批量请求并求解二分分配最小化所有乘客的平均接驾时间。
为什么 GPS 用至多一次而支付用至少一次?丢一个 GPS 包影响可忽略(下一个 5 s 内到);丢一个支付事件有真实金融后果。投递保证应匹配丢失消息的业务成本。
为什么按城市和产品类型分区司机位置数据?UberX 和 UberPool 从独立司机池抽取;跨城供应无关。分区按市场隔离负载并使每段内的匹配查询快。
怎么防止司机被双重匹配?匹配服务在发邀约前原子把司机状态从 AVAILABLE 翻到 IN_TRIP。任何并发匹配尝试读到更新的状态并跳过那个司机。
surge 乘数怎么算?每 60–120 s,按 geohash cell 计数 pending_requests 和 available_drivers;算它们的比率;映射到一个乘数表;写到 Redis 带短 TTL。定价读是 Redis 命中——绝不直接查空间索引。