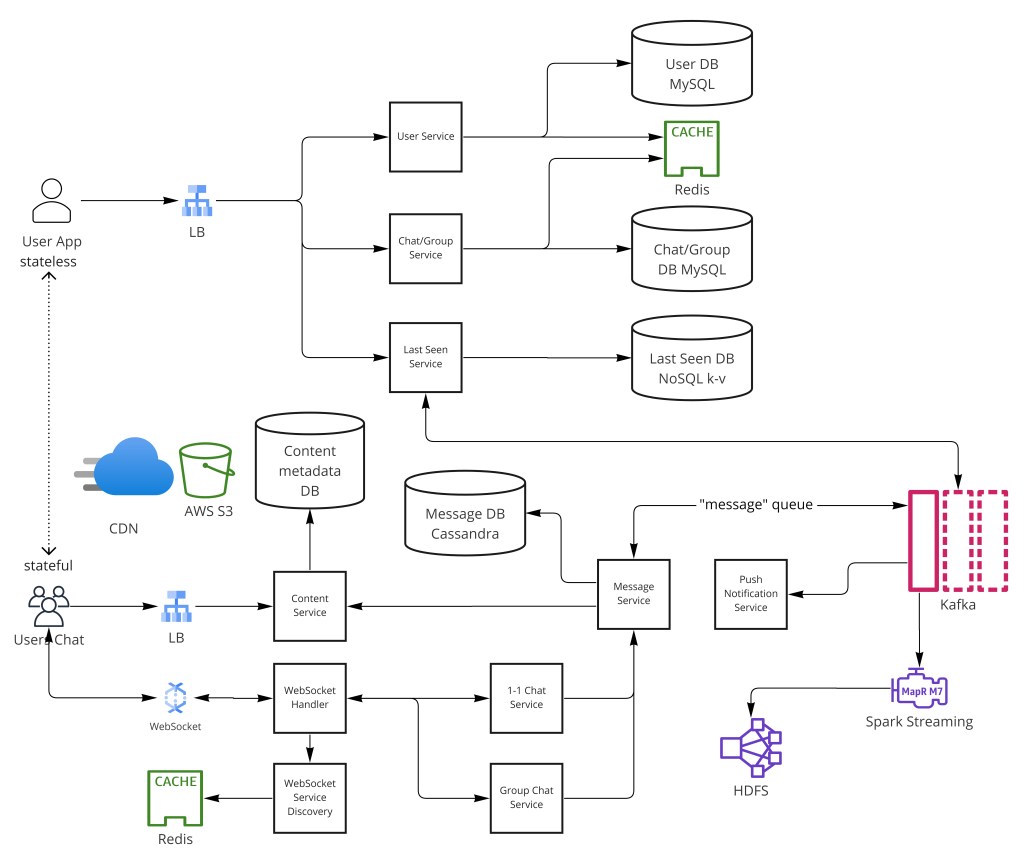
聊天应用坐落在系统设计最苛刻的交叉点之一:它必须处理数十亿用户、每天数千亿条消息、亚秒投递延迟、可靠的离线排队和复杂的群组语义——同时维护端到端加密和准确的在线状态信息。核心挑战是每条消息必须被投递到一个特定设备,而不只是一条数据库记录——这意味系统必须跨数千台服务器跟踪实时连接状态,并实时把消息路由到恰好正确的服务器。
- WebSocket——持久全双工连接消除轮询延迟;每客户端单连接支持真正的服务端推送。
- WebSocket Manager(Redis KV)——映射 user_id → websocket_server:port;让任何服务能跨 65K+ 端口把消息路由到正确服务器。
- Snowflake ID——64 位:41 位 ms 时间戳 + 10 位机器 ID + 12 位序列;分布式唯一 ID 带内建时间排序用于消息显示。
- 在线 vs 离线投递——在线:直接 WebSocket 投递;离线:Pending 状态 + 推送通知(APNs/FCM)直到重连。
- 写扇出 vs 读扇出——写扇出在发送时把消息复制到每个接收者的信箱;读扇出在读时查询共享消息存储。小群写扇出胜,大群读扇出胜。
- 群大小上限——有界扇出成本(微信 500 人上限);每条群消息需每成员一次投递。
- last seen 采样——~1 分钟间隔轮询在线状态;接受轻微精度损失以避免 4B 用户下的写风暴。
用 WebSocket 做全双工、持久的客户端-服务器连接。通过一个把用户 ID 映射到服务器的 WebSocket Manager(键值存储)路由消息。用 Snowflake 生成消息 ID(时间有序、分布式、64 位)。对离线用户把消息排队为"pending"并经推送通知投递。1:1 和小群用写扇出;大群切到读扇出(共享消息日志)。给群大小设上限以约束最坏扇出成本。
第 1 步 — 澄清需求
聊天应用从简单的 1:1 短信式消息到实时协作工作区不等。画任何图前界定问题。
功能
- 用户注册和认证。
- 带可靠投递的一对一消息。
- 群聊(有界大小——如最多 500 成员)。
- 媒体支持:文本、图片、音频、视频片段。
- 已读回执(已发送 / 已送达 / 已读指示)。
- last seen / 在线状态跟踪。
- 消息历史和搜索。
非功能
- 低延迟——实时感是核心产品承诺;给在线接收者 <100 ms p99 投递。
- 高可用——掉线或漏消息摧毁信任;目标 99.99%。
- 海量规模——40 亿用户,每天 1000 亿条消息。
- 消息有序——一个会话内的消息必须在所有设备上按发送顺序出现。
- 应用级 exactly-once 投递保证——无重复消息,即便重试。
第 2 步 — 容量估算
WhatsApp / 微信规模:40 亿用户,大约 10 亿日活(DAU)。每 DAU 发 ~100 条消息/天。
消息量
- 1B DAU × 100 消息/天 = 1000 亿条消息/天。
- 100B ÷ 86,400 秒 = ~115 万条消息/秒平均;3× 峰值因子 → ~350 万条/秒。
- 每条消息:~1 KB 平均(含元数据)→ 3.5M × 1 KB = 峰值 ~3.5 GB/秒消息数据。
WebSocket 连接
- 1B DAU,每个一条持久 WebSocket 连接 → 10 亿并发连接。
- 单台服务器能处理 ~100K 并发 WebSocket 连接(每连接用 ~10 KB RAM 存状态)→ 需要 10,000 台 WebSocket 服务器。
- 每台服务器在多达 65,535 个端口上监听;实践中连接在每服务器单端口上多路复用,所以限制因素是 RAM、不是端口数。
存储
- 100B 消息/天 × 1 KB × 365 = ~36 PB/年消息数据。
- 大多数用户保留消息数年 → 消息按用户预期无限期存储,从热(近 90 天在 Cassandra)分层到冷(更旧,对象存储里压缩)。
- 媒体附件是主导存储成本:1% 消息的 1 MB 照片 = 1B 媒体项/天 × 1 MB ≈ 1 PB/天媒体。媒体存储前按哈希去重。
第 3 步 — API 设计
# Auth
POST /api/auth/login
{ phone_number, otp }
→ { access_token, refresh_token }
# WebSocket 连接(升级)
GET /ws/connect
Authorization: Bearer {access_token}
→ 101 Switching Protocols
注册: user_id → ws_server:port 进 WebSocket Manager
# 发消息(经 WS 帧,非 REST)
-- 客户端发 WS 帧:
{ type: "message", idempotency_key: "uuid",
receiver_id: 456, content: "hello", media_url: null }
-- 服务器回复:
{ type: "ack", message_id: 7234567890123, status: "sent" }
# REST: 消息历史(按 cursor 分页)
GET /api/conversations/{conv_id}/messages?before_id=7234567890123&limit=50
# REST: 创建群
POST /api/groups
{ name, member_ids: [1, 2, 3 ...] }
# REST: 上传媒体(返回 CDN URL)
POST /api/media/upload
Content-Type: multipart/form-data
→ { media_url, media_id }发消息经 WebSocket 连接发生,不经 REST,因为连接已开着、加 REST 往返会浪费持久连接。idempotency_key 由客户端生成(UUID)并在重试时防止重复消息创建——若客户端发同键两次(如因为 ACK 丢失),服务器返回已创建的消息 ID 而不创建第二条消息。
第 4 步 — 协议选择:为什么 WebSocket
聊天的核心挑战是服务器到客户端的消息推送。存在三种方法:
| 协议 | 问题 |
|---|---|
| 短轮询 | 延迟由轮询间隔决定;频繁轮询浪费资源,不频繁轮询感觉卡 |
| 长轮询 | 反复连接建立/拆除开销;多个同时请求能造成消息有序问题 |
| WebSocket | 持久全双工连接;消除轮询开销;支持真正的实时双向消息 |
| Server-Sent Events (SSE) | 仅服务端推送;客户端无法经同一连接发送;发送仍需单独 HTTP 通道 |
WebSocket 胜出,因为它们每客户端维护一条持久连接,使服务器能在消息到达瞬间推送、无轮询延迟、无连接重建开销。连接在用户会话生命周期内保持开着;每 30 秒一次心跳 ping/pong 检测死连接而无需客户端轮询。
第 5 步 — 核心服务
- 用户服务(User Service)——用户 CRUD、认证和联系人管理的 RESTful API。
- 聊天 / 群组服务——管理会话创建、删除和群成员;存
[group_id, member_list, admin_ids]。 - 消息服务(Message Service)——持久化消息、生成 Snowflake ID、发布事件到 Kafka 供下游处理。
- WebSocket 网关——维护长生命周期客户端连接的有状态服务器;处理 WS 帧解析、心跳和连接生命周期。
- WebSocket Manager——维护
user_id → websocket_server:port的键值映射;由 Redis 支撑做快速内存查找。这是让任何服务为任何用户找到正确 WebSocket 服务器的路由表。 - 通知服务(Notification Service)——给离线用户派发推送通知(iOS 用 APNs、Android 用 FCM)。
- 在线状态服务(Presence Service)——跟踪在线/离线状态和 last-seen 时间戳。
- 媒体服务(Media Service)——接收二进制上传、存进对象存储、返回 CDN URL 以嵌入消息。
第 6 步 — 数据模型
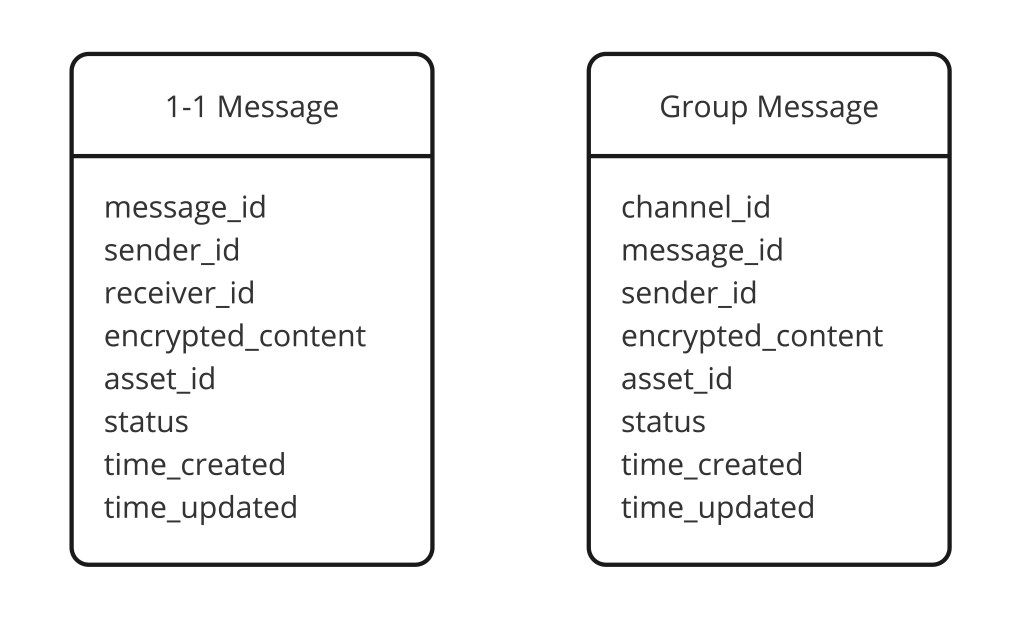
-- 消息表:按会话分区以高效读历史
CREATE TABLE messages (
conversation_id BIGINT,
message_id BIGINT, -- Snowflake ID(时间有序)
sender_id BIGINT,
content TEXT, -- 静态加密
media_url TEXT, -- 纯文本则 null
status ENUM, -- Sent | Delivered | Read
idempotency_key UUID, -- 重试去重
created_at TIMESTAMP,
PRIMARY KEY ((conversation_id), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
-- 用户收件箱:每个用户的会话列表带未读计数
CREATE TABLE user_inbox (
user_id BIGINT,
conversation_id BIGINT,
last_message_id BIGINT,
unread_count INT,
updated_at TIMESTAMP,
PRIMARY KEY (user_id, updated_at)
) WITH CLUSTERING ORDER BY (updated_at DESC);
-- 群成员
CREATE TABLE group_members (
group_id BIGINT,
user_id BIGINT,
role TEXT, -- member | admin
joined_at TIMESTAMP,
PRIMARY KEY (group_id, user_id)
);
-- 投递回执:每消息每接收者状态
CREATE TABLE receipts (
message_id BIGINT,
recipient_id BIGINT,
status TEXT, -- Delivered | Read
updated_at TIMESTAMP,
PRIMARY KEY (message_id, recipient_id)
);消息表按 conversation_id 分区,使最常见查询——"加载这个会话的最后 50 条消息"——是单分区扫描。聚簇键 message_id(一个 Snowflake ID)在分区内按时间保持消息有序。Cassandra 是这里正确的存储,因为写模式(高吞吐、仅追加)和读模式(分区内按时间范围扫描)完美映射到 Cassandra 的强项。
第 7 步 — 消息 ID 生成:Snowflake
消息 ID 必须全局唯一、时间有序(使消息在 UI 里正确排序而无需单独时间戳排序),且无需协调生成(使没有单点故障 ID 生成器)。Snowflake ID 满足全部三个需求:
Snowflake 64 位 ID 布局:
┌─────────────────────────────┬──────────────┬──────────────────┐
│ 41 位: ms 时间戳 │ 10 位 nodeID │ 12 位序列 │
│ (epoch 偏移, ~69 年) │ (1024 节点) │ (4096/ms/节点) │
└─────────────────────────────┴──────────────┴──────────────────┘
最大吞吐: 1024 节点 × 4096 ID/ms = 4.19 百万 ID/ms
时间排序: 较晚生成的 ID 数值上总更大
无协调: 每个节点独立生成41 位时间戳字段(自定义 epoch 以来的毫秒)意味 ID 无需单独 created_at 字段就可排序——直接比较两个 Snowflake ID 就告诉你哪条消息先来。10 位节点 ID(每个消息服务实例启动时配置)保证跨机群唯一而无任何全局锁或集中 ID 服务。
第 8 步 — 消息投递:在线 vs 离线
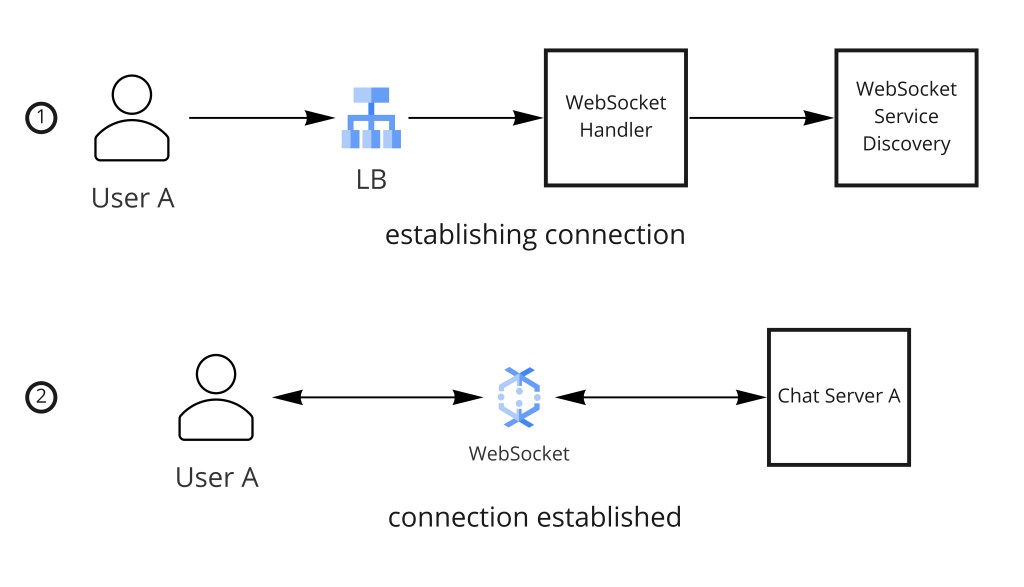
一条消息被发送时,消息服务通过查询 WebSocket Manager 检查接收者是否有活跃 WebSocket 连接。两条路径分叉:
发送者经 WebSocket 发消息
→ WebSocket 网关接收 WS 帧
→ 消息服务:
1. 去重检查: idempotency_key 在 Redis(TTL 24h)
2. 生成 Snowflake message_id
3. 持久到 Cassandra(status: Sent)
4. 给发送者发 ACK: { message_id, status: "sent" }
5. 在 WebSocket Manager 查接收者
[接收者在线]
→ 转发到接收者的 WebSocket 服务器(经内部 RPC)
→ WebSocket 服务器推到客户端 WS 连接
→ 接收者客户端 ACK 回执
→ 消息服务更新 status: Delivered
→ 经 WS 把 Delivered 回执推给发送者
[接收者离线]
→ 消息留在 Cassandra(status: Pending)
→ 通知服务发推送通知(APNs/FCM)
→ 接收者重连时:
客户端发 { last_seen_message_id: 7234567890000 }
服务器返回所有 id > last_seen 的消息
服务器更新 status: Delivered
发送者收到 Delivered 回执At-Least-Once 投递与去重
系统在网络级别保证至少一次投递——一条消息在重试时可能被尝试多次。应用层必须去重以达到用户可见的 exactly-once 保证。去重键是客户端提供的 idempotency_key(UUID),存在 Redis 里带 24 小时 TTL。重试时,消息服务在写 Cassandra 前检查 Redis;若键存在,它返回已存在的消息 ID 而不创建重复。
第 9 步 — 扇出:写扇出 vs 读扇出
扇出是决定消息如何从发送者到达所有接收者的架构决策。有两种根本不同的方法,各有不同取舍:
| 方法 | 怎么工作 | 写成本 | 读成本 | 最适合 |
|---|---|---|---|---|
| 写扇出(推模型) | 发送时把消息复制进每个接收者的信箱/收件箱 | O(N) 写,N = 接收者 | O(1) 每用户收件箱扫描 | 小群、DM;N 有界 |
| 读扇出(拉模型) | 消息在共享日志里存一次;每个接收者读时取 | O(1) 写 | O(成员) 每读(每个读者扫描共享日志) | 大群、公开频道;写成本会爆炸 |
混合策略
生产系统(WhatsApp、Slack、Telegram)用混合:
- 1:1 消息和小群(<100 成员)——写扇出:发送时消息服务往每个接收者的收件箱写一条投递记录。每个接收者的收件箱扫描在读时 O(1)。~100 次写的写成本可忽略。
- 大群(>100 成员)——读扇出:消息在一个共享会话日志里存一次。成员打开会话时,他们用一个 cursor 查日志("给我自我上次已读位置以来的消息")。这避免 5,000 成员频道的 O(5000) 写成本。
- 极大公开频道——读扇出配每用户存为简单整数的单独"未读计数",避免为算徽章计数而扫描完整消息日志。
写扇出用写放大换快读;读扇出用写简单换读复杂。交叉点大约是 100–200 成员:低于此,写扇出胜;高于此,读扇出避免 O(N) 写风暴。
第 10 步 — 群聊与有序保证
群消息把 receiver_id 换成 conversation_id 且必须同时投递给所有群成员。这个扇出是群聊主要的可扩展性挑战:一条给 500 人群的消息需要 500 次单独投递尝试。设计给群大小设上限(微信 500 人上限是参考)以约束最大扇出成本和投递滞后。
会话内消息有序
两个用户同时发消息能都"赢"并产生有序冲突。解法是用 Snowflake ID 作权威排序键——消息总按 message_id 升序显示。因为 Snowflake ID 含一个毫秒时间戳,同一毫秒从不同节点发的两条消息由节点 ID 位区分,即便并发发送也确保一个确定全序。
对严格因果有序要紧的会话(如"回复消息 X"),消息 schema 里含一个 reply_to_message_id 字段。客户端 UI 通过跟随这些链接渲染线程视图,无论消息的到达顺序。
第 11 步 — 已读回执
标志性的双勾 / 蓝勾指示(已发送 → 已送达 → 已读)是一个已读回执系统。实现细节:
- 已发送(Sent)——发送者客户端从消息服务收到带分配
message_id的 ACK。一个勾。 - 已送达(Delivered)——接收者设备收到消息并经 WebSocket 发回投递 ACK。消息服务更新
receipts表并把Delivered事件推给发送者。两个勾。 - 已读(Read)——接收者应用标消息已读(用户打开会话)。客户端经 WebSocket 发
ReadReceipt帧。两个蓝勾。
对群消息,发送者只在每个成员都在 receipts 表里有 Delivered 回执时才看到"已送达所有人"。这是每次"已送达所有人"检查 O(成员) 次读——WhatsApp 对群显示每成员下钻列表而非单个聚合指示的原因。
批处理回执写
在 100B 消息/天,单个回执写会再给数据库加 200–300B 写/天(每消息两个回执)。通知服务批处理回执更新:投递 ACK 在 Redis 累积 500 ms,然后在单个批写里刷到 Cassandra。这把写放大降低 ~50–100×。
第 12 步 — 在线状态与 Last Seen
跟踪"这个用户在线吗?"和"他们上次何时用应用?"听起来简单,但在 40 亿用户的聊天系统里是最难的可扩展性问题之一。
朴素方法及为什么失败
最简单的实现会让每个用户每秒把当前时间戳写到数据库。1B DAU × 1 写/秒 = 10 亿写/秒——这显然不可能。
经心跳采样的在线状态
在线状态服务用一个采样方法:
- WebSocket 网关每 60 秒给每个活跃连接向在线状态服务发心跳:
{ user_id, online: true }。 - 1B 活跃连接 × 1 写/60 秒 ≈ ~16.7M 写/秒——仍很高,但用分片 Redis 集群可管理。
- 每个用户的在线状态存在 Redis 里作一个 TTL 90 秒的 key。若 TTL 内无心跳到达,key 过期、用户被视为离线。
- "last seen" 时间戳只在断开或在线时每小时一次写到 Cassandra,而非每次心跳。这把 Cassandra 写负载降低 3600×。
在线状态订阅(联系人的在线状态)
用户想知道哪些联系人在线。朴素方法(每次页面加载为每个联系人查在线状态服务)每用户打开产生 O(联系人) 个请求。生产方法用一个 pub-sub 模型:
- 当用户 A 上线,在线状态服务把一个
online事件发布到按user_id_A为键的频道。 - 任何有用户 A 联系人列表订阅者的 WebSocket 服务器(即 A 的一个好友已连接)收到事件并把它推到那个好友的 WebSocket 连接。
- Redis Pub/Sub 或一个专用在线状态 broker(如一个轻量 MQTT broker)处理扇出。
第 13 步 — 媒体存储
图片、音频和视频不内联存在消息对象里。相反,消息记录持有一个 CDN URL,实际二进制内容住在对象存储。上传流程:
- 客户端调
POST /api/media/upload。 - 媒体服务生成一个预签名 S3 上传 URL 并连同一个
media_id返回。 - 客户端经预签名 URL 直接上传到 S3(完全绕过应用服务器)。
- S3 触发一个 Lambda/事件通知媒体服务上传完成。
- 媒体服务记录
media_id → CDN URL映射并把 CDN URL 返回给客户端。 - 客户端把 CDN URL 包含在消息载荷里。
媒体去重:上传前,客户端计算文件的 SHA-256 哈希并发给媒体服务。若哈希已存在数据库(另一用户已上传同文件),服务器返回已存在的 CDN URL 而无新上传——重复零字节传输。这对病毒媒体(表情包、语音)尤其有效,那里同一文件被数千用户分享。
第 14 步 — 扩展与容错
WebSocket 服务器扩展
- WebSocket 服务器有状态(它们持有开着的连接)但路由状态被外置到 WebSocket Manager(Redis)。加一台新服务器只需向负载均衡器注册它——无状态迁移。
- 服务器崩溃时,客户端自动重连(带抖动指数退避)。客户端重连时发它的
last_seen_message_id,服务器投递自那 ID 以来的所有待处理消息。 - 崩溃服务器的 WebSocket Manager Redis 条目由一个健康检查 watchdog 清理,它在服务器停止发心跳时移除陈旧条目。
消息的 Cassandra 分片
- 消息按
conversation_id分区。Cassandra 用一致性哈希把分区分布在节点上,所以加节点重分布负载而无需全量重分片。 - 热门会话(一个庞大群聊)能使单个分区成热点。缓解:在分区键里给时间分桶——
conversation_id + month作复合分区键,使消息历史分布在基于时间的桶上。
消息队列与重放
消息服务在持久到 Cassandra 前把每条进来的消息发布到 Kafka。这服务两个目的:它把写路径与下游消费者(通知服务、分析、搜索索引器)解耦,且它支持重放——若一个消费者落后或崩溃,它能从它最后提交的 Kafka offset 重放而不丢消息。
关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| 实时投递 | WebSocket(持久) | 有状态服务器;比无状态 HTTP 更难横向扩展 |
| 消息 ID 生成 | Snowflake(分布式) | 节点 ID 必须谨慎分配;时钟偏移能造成罕见有序问题 |
| 扇出策略 | 混合(写 <100,读 >100) | 两条代码路径的复杂度;每平台需调阈值 |
| 消息存储 | Cassandra(按会话分区) | 无跨会话查询;分析必须用单独 OLAP 存储 |
| 在线状态跟踪 | 采样心跳(60s) | 在线状态略陈旧;"last seen 5 分钟前"可能偏差最多 60s |
| 投递保证 | 至少一次 + 客户端去重 | 客户端必须处理并丢弃重复(idempotency_key 检查) |
聊天设计主要关于三个难问题:实时投递(WebSocket + WebSocket Manager 做路由)、离线排队(Pending 状态 + 推送通知 + 重连时追赶),和扇出策略(小群写扇出,大群读扇出)。Snowflake ID 用内建时间排序解决分布式唯一 ID 生成。群大小上限是一个显式可扩展性杠杆。在线状态采样用轻微精度换写吞吐——经典的可用性-一致性取舍应用到一个不明显的维度。
当数百万 WebSocket 连接散布在许多服务器上时,怎么把消息路由到正确服务器?一个 WebSocket Manager(Redis 支撑)存 user_id → server:port;任何服务能 O(1) 查目标服务器并经内部 RPC 转发消息。
为什么给群聊大小设上限?一条群消息扇出到每个成员——1,000 人群意味 1,000 次单独投递。设上限约束最坏扇出延迟并防止单条消息饱和投递管道。
消息发给离线用户会怎样?消息以 Pending 状态存储;一个推送通知(APNs/FCM)唤醒接收者设备;重连时客户端发它的 last-seen ID,服务器投递所有漏掉的消息,状态更新为 Delivered。
写扇出 vs 读扇出——何时用各个?写扇出在发送时复制到每个收件箱(快读,O(N) 写)——用于 DM 和小群。读扇出在共享日志里存一次(O(1) 写,O(成员) 读)——用于写放大会过高的大群。
怎么在重试时防止重复消息?客户端生成的幂等键(UUID)存在 Redis 里带 24 小时 TTL。消息服务写前检查键;若已存在,返回已存在的消息 ID 而不创建重复。