分片(sharding)是一种把数据库水平分区到多个独立节点(每个叫一个分片)的技术,让数据集和写负载被分散而非集中在单台机器上。当单台数据库服务器再也扛不住数据量或查询吞吐——且垂直扩展(更大 CPU、更多 RAM)已触顶时,分片是下一步。但分片不是免费午餐:它用一个简单、强一致的单节点模型,换来一个让跨分片查询、事务和 schema 变更都急剧变难的分布式系统。理解何时以及如何分片——以及用三种核心策略里的哪一种——是你将做出的最有后果的架构决策之一。
本指南覆盖完整的分片决策空间:水平 vs 垂直分区、三种分片策略的深入、一致性哈希算法和虚拟节点为何重要、分片键选择标准、热点管理、最小中断的重分片、跨分片查询处理、分布式事务,以及分片与复制的关系。读完你将拥有做出自信分片决策的词汇和心智模型——并能在系统设计面试中清晰表述取舍。
- 哈希分片给出均匀分布但破坏范围查询,且节点数变化时需要全量数据迁移——除非你用一致性哈希。
- 范围分片支持高效范围扫描但在时间戳、自增 ID 等顺序键上有写热点风险。
- 目录分片提供最大灵活性,代价是关键路径上有一个高可用查找服务。
- 一致性哈希在加一个节点时把数据移动最小化到 ~k/n 个 key;虚拟节点平滑不均分布。
- 分片键设计是最有后果的决策——高基数、写均匀分布、与查询模式对齐。
- 跨分片 join 必须在应用层做(取数 + 内存合并)——通过围绕访问模式设计分片键来避免它们。
- 分片和复制是正交的——每个分片本身应被复制以实现 HA;你两者都需要,不是二选一。
分片按分片键把数据切到多个数据库节点上。哈希分片给均匀分布;范围分片支持高效范围扫描;目录分片提供最大灵活性。一致性哈希在重分片时把数据移动最小化。代价是真实的复杂度:跨分片查询、join 和事务需要大量工程投入。只在耗尽垂直扩展、读副本和缓存之后才分片。
分片之前:扩展阶梯
分片是一项昂贵的运维承诺。在动手之前,按顺序耗尽扩展阶梯上的选项——每一步增加的复杂度都比分片小:
- 垂直扩展——给主库更多 CPU、RAM 和更快存储。直截了当,但受限于商用最大实例类型。一台现代云实例可载 192 vCPU 和 3 TB RAM,处理每秒数十万查询——大多数负载从不需要超过这个。
- 读副本——把读流量路由到副本;把写集中在主库。对读多的负载(90:1 或更高读写比)通常带来 5–10 倍有效读容量。主库仍在写上成为瓶颈。
- 缓存——一个吸收 95% 读流量的 Redis 缓存意味着你的数据库只见 5% 的完整负载。有效容量增益巨大,且无需数据架构变更。
- 功能拆分(垂直分区)——把不同业务域拆成独立数据库,各跑在自己的服务器上。订单库、目录库、用户库各自独立扩展,而无任何单表行级拆分。
- 分片(水平分区)——当单张表即使做了上述步骤后对一台服务器仍太大或太热,把它的行切到多个分片。
一个带副本和 Redis 缓存的单 PostgreSQL 主库能轻松处理 10 万读/秒和 1 万写/秒。在 100 万读/秒或 10 万写/秒时,你开始需要在写路径上分片。大多数初创公司从未达到那个规模。在痛苦真实时分片,而非在架构图看起来更酷时。
垂直 vs. 水平分区
"分区(partitioning)"这个词的含义因你沿列轴还是行轴拆分而不同。理解这个区别重要,因为它们解决不同问题且常一起用。
| 维度 | 垂直分区 | 水平分区(分片) |
|---|---|---|
| 拆什么 | 列——不同表/列在不同服务器(功能拆分) | 行——同一张表分散到多个节点 |
| 扩展上限 | 受限于你能划出的域边界数量 | 随节点数横向扩展——理论上无界 |
| 引入的复杂度 | 跨服务 API 调用代替 join;服务边界设计 | 跨分片查询、分布式事务、重分片运维 |
| 用例 | 微服务拆分、分离读多与写多的列 | 单表超过一台服务器容量(用户、事件、消息) |
| 示例 | 用户服务库、订单服务库、商品服务库 | 用户 1–10M 在分片 1,用户 10M–20M 在分片 2,... |
垂直分区(功能拆分)本质就是微服务做的事:每个服务拥有自己的数据库,服务通过 API 而非 SQL join 通信。这常是正确的第一步,因为它消除跨域 join、允许独立扩展、并干净映射到团队所有权——而无任何水平分片的行级复杂度。
当单个服务的表增长超过一台服务器能处理时,水平分片才登场。经典例子:有 20 亿用户的社交平台、每天处理 1 亿交易的支付系统、存 1 万亿消息的消息系统。没有垂直拆分能解决这些——表本身必须跨机器切分。
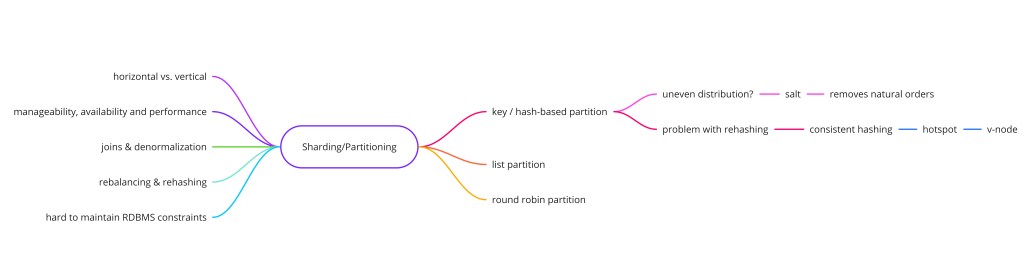
三种分片策略
哈希分片(Hash-Based)
对分片键应用哈希函数并计算 shard_id = hash(key) % num_shards 来决定哪个分片持有给定行。哈希函数无视键的自然排序而均匀分布值,所以数据和写负载均匀分散到所有分片。
def get_shard(user_id: int, num_shards: int) -> int:
# 跨分片一致性哈希——均匀分布
return hash(user_id) % num_shards
# user_id=1234567,8 个分片 → 分片 3
# 用户 1234567 的所有数据都在分片 3
# 范围查询 "users WHERE id BETWEEN 1M AND 2M" → 必须查所有 8 个分片- 优点:均匀分布——除非键空间本身倾斜,否则没有单个分片变得过大。所有分片写负载均匀。
- 缺点:范围查询需要对所有分片做 scatter-gather 扇出并在应用层合并。增删分片改变
num_shards并重映射几乎每个 key——一次影响(N-1)/N * total_data行的全量数据迁移。 - 最适合:查询总包含分片键(按 user_id、order_id 点查)、范围扫描罕见或路由到单独分析副本的负载。
范围分片(Range-Based)
把行分区成分片键的连续范围——如用户 ID 1–1,000,000 在分片 1、1,000,001–2,000,000 在分片 2。分片边界在一个把每个范围映射到分片的路由表里显式定义。
- 优点:针对连续键范围的范围查询只命中相关分片——常见的时间或顺序查询无需 scatter-gather。容易推理数据放置。对查询频繁针对近期窗口的时序数据高效。
- 缺点:热点风险——最关键的失效模式。若近期数据最活跃(时间戳或自增 ID 几乎总是如此),最高范围的分片(含最新数据)承担几乎所有写负载,而较旧的分片大多冷着。这完全抵消分片的写吞吐增益。
- 最适合:时间分区的归档数据,旧数据冷且查询频繁针对特定日期窗口。除非你预先分片以分散"热"范围,否则不适合作为活跃写负载的主策略。
对活跃写负载,避免用时间戳或顺序自增 ID 作范围分片键。改用一个把哈希前缀和时间戳结合的复合键:shard = crc32(user_id) % 16 决定初始分片,而在该分片内数据按时间序存储。这在分片内给出范围查询效率,同时把写分散到所有分片。
目录分片(Directory-Based)
一个集中查找表("目录")显式把每个 key(或 key 范围)映射到其目标分片。每个数据库请求先查目录找到正确分片,再直接查那个分片。目录本身必须高可用且极低延迟,因为它在每个数据库操作的关键路径上。
- 优点:最大灵活性——任何 key 可在任何时候重映射到任何分片,而无需改哈希或范围逻辑。允许渐进、外科手术式的数据迁移:把特定热租户或账号移到专用分片而无需重分片全部。干净处理租户级隔离需求(多租户 SaaS,每个企业客户得到自己的分片)。
- 缺点:目录是单点故障和潜在性能瓶颈;它必须被复制(通常通过 Raft 等强一致共识)、激进缓存,并以与主数据库同样的可靠性严格对待。给每个查询加一个延迟下限(通过本地缓存目录缓解)。
- 最适合:多租户平台、需要不规则或策略驱动数据放置的场景,以及偏好外科手术式逐 key 迁移而非批量数据移动的渐进重分片操作。
| 策略 | 分布 | 范围查询 | 重分片成本 | 灵活性 |
|---|---|---|---|---|
| 哈希分片 | 均匀 | scatter-gather 所有分片 | 高(重映射 ~所有 key) | 低(固定算法) |
| 范围分片 | 不均(热点风险) | 单个或少数分片 | 中(拆分范围) | 中(范围可调) |
| 目录分片 | 可配置 | 取决于映射 | 低(更新映射) | 高(任意放置) |
| 一致性哈希 | 带 vnode 均匀 | scatter-gather | 低(~k/n 个 key 移动) | 中 |
一致性哈希:算法深入
标准取模哈希分片有一个灾难性的重分片问题:给 8 节点集群加一个节点把模数从 8 变到 9,使 7/8 ≈ 88% 的所有 key-分片映射失效。每一个这样的 key 都必须迁到新分片。这对一个在线生产系统贵得离谱。一致性哈希优雅地解决了它。
环抽象
一致性哈希把节点和 key 都映射到一个整数逻辑环(通常是完整 MD5 或 SHA-1 哈希空间:0 到 2128–1)。每个节点被放在由哈希其标识符决定的环上位置。每个 key 被放在由哈希 key 本身决定的位置。一个 key 由从其位置顺时针最近的节点拥有。
加节点时,它被放在环上一个新位置,只认领它与其逆时针邻居之间的 key 范围。所有其他 key 分配不受扰动。移除节点时,它的 key 范围传给其顺时针后继。两种情况下,只有 ~k/n 个 key 移动——总数据集中与新增或移除容量成比例的一部分。
import hashlib
from sortedcontainers import SortedDict
class ConsistentHashRing:
def __init__(self, virtual_nodes=150):
self.ring = SortedDict() # 按哈希位置排序
self.vnodes = virtual_nodes
def _hash(self, key: str) -> int:
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def add_node(self, node: str):
for i in range(self.vnodes):
h = self._hash(f"{node}#vn{i}")
self.ring[h] = node # 每个物理节点 150 个虚拟节点
def remove_node(self, node: str):
for i in range(self.vnodes):
h = self._hash(f"{node}#vn{i}")
del self.ring[h]
def get_node(self, key: str) -> str:
if not self.ring:
raise ValueError("Ring is empty")
h = self._hash(key)
idx = self.ring.bisect_right(h) % len(self.ring)
return self.ring.peekitem(idx)[1] # 顺时针最近节点虚拟节点:为什么是 150?
物理节点数少(比如 3 个)时,哈希函数把它们均匀放在环上的概率低——你可能落得一个节点拥有 60% 的 key 空间、另一个拥有 15%。虚拟节点通过给每个物理节点分配环上多个位置解决这个(150 是 Cassandra 默认)。每个物理节点 150 个虚拟节点,大数定律生效,负载平衡到理想值的几个百分点内。取舍是内存——环表按虚拟节点数增长,但即便 100 个物理节点各 1000 个虚拟节点,环表也只有 10 万条目,小到可忽略。
虚拟节点也简化异构集群:一个有两倍内存和 CPU 容量的节点可被分配 300 个虚拟节点而非 150,使它拥有 ~两倍 key 空间并承担两倍流量——而路由逻辑无需任何特殊处理。
分片键设计:最有后果的决策
分片键是决定哪个分片持有给定行的列(或列组合)。坏分片键造成热点、迫使常见查询 scatter-gather,或破坏应用层 join 模式。一旦数据分片,改分片键极具破坏性——它需要跨分片全表重洗。在写第一行之前把这个做对。
好分片键的属性
- 高基数——足够多的不同值把数据无冲突地分散到所有分片。一个布尔列(活跃/不活跃)基数为 2——作分片键灾难性地糟。UUID 或高基数 ID 列工作良好。
- 写均匀分布——写在键值空间上的分布应均匀。单调递增的键(自增 ID、时间戳)在哈希分片下失败,因为"当前"值总是最高的,集中了写。改用哈希或 UUID 派生的键。
- 与访问模式对齐——最重要的单一属性。若你最常见的查询是"取用户 X 的所有订单",按
user_id分片订单意味着该查询恰好命中一个分片。按order_id分片把一个用户的订单分散到所有分片,迫使每个面向用户的请求扇出。 - 稳定——若分片键值改变(如用户改了你天真地用作分片键的 email),该行需要移到不同分片。不可变的键(内部 UUID、插入时生成的自增 ID)完全避免这个问题。
真实世界的分片键例子
- 社交平台用户表——按
user_id分片(哈希)。所有按用户读都是单分片。跨用户分析扇出到所有分片并重定向到数仓。 - 电商订单表——按
user_id分片(不是order_id!)让"我的订单"读是单分片。商家侧"商品 X 的所有订单"必须扇出——若路由到单独分析副本则可接受。 - 时序 IoT 事件表——按
device_id分片(哈希)让一个设备的所有事件共置、单设备时间窗查询是单分片。仅按时间戳分片会把所有当前写集中到一个分片。 - 多租户 SaaS——用目录按
tenant_id分片,让大企业客户能被隔离到专用分片、小客户共置在共享分片。
热点与重分片
热点:当一个分片成为瓶颈
热点发生在不成比例的读或写路由到单个分片时。这可能因三个原因:
- 倾斜的键分布——若分片键的值分布不均(如大多数用户在一个地理区域),哈希分片不会均匀分布。
- 热实体——社交平台上一个名人用户可能有 5000 万关注者,全在同一分片产生事件。没有分片键设计能完全防止实体级热点;缓解是反规范化(把事件扇出到关注者分片)或在热分片前加缓存层。
- 范围分片下的基于时间的写——"当前"范围分片吸收所有写。缓解:用哈希分片做写分布、范围分片只用在分析/归档层。
重分片:不做全量迁移就增加容量
随着数据增长,单个分片填满、性能退化。重分片——拆分现有分片或加新的——是分片系统中运维最密集的任务之一。技术大致从最小到最大破坏性:
- 读副本提升——若一个分片写热但读多,把一个副本提升为独立处理读的共主。这买到时间但并未真正拆分数据。
- 分片拆分——把一个过载分片分成两个。范围分片:更新路由表里的边界并把上半行迁到新分片。一致性哈希:给环加一个新节点;只有新节点与其前驱之间的 key 范围迁移。
- 在线 schema 变更工具——当重分片需要跨所有分片的 schema 变更时,用
gh-ost(GitHub 的在线 Schema 变更)或pt-online-schema-change做变更而不阻塞生产写。 - 双写 + 回填模式——同时写旧和新分片布局,同时一个后台作业把现有数据从旧拷到新。一旦回填完成并验证,把读切到新布局并停止双写。这允许零停机重分片,代价是临时写放大。
# 在线重分片:双写 + 回填模式
阶段 1 — 双写(无停机):
所有写 → 旧分片 和 新分片布局
读仍由旧分片服务
阶段 2 — 回填(后台):
把所有现有行从旧 → 新布局拷贝
按主键范围跟踪进度
每批验证校验和
阶段 3 — 切换(短暂读暂停或零停机):
验证新分片与旧完全一致
把读切到新分片布局
停止对旧布局的双写
阶段 4 — 清理:
验证期后删除旧分片数据跨分片查询与事务
跨分片查询:scatter-gather 问题
任何 WHERE 子句不含分片键的查询都必须广播到所有分片(scatter),并在应用层合并结果(gather)。这叫 scatter-gather 扇出,是分片系统中最常见的性能问题:
- 查询延迟受最慢分片限制,而非平均。若 16 个分片中 1 个慢,所有扇出查询都等它。
- 扇出查询产生
N个查询,N是分片数。64 个分片时,单个面向用户的请求产生 64 个数据库查询。这给有效并发用户容量封顶。 - 应用层的结果合并(排序、去重、聚合)给应用层加 CPU 和内存压力。
缓解:
- 设计分片键与你最常见的查询模式对齐——这是唯一真正的修法。接受其他查询模式会更贵。
- 把分析/跨分片查询路由到单独的数仓或 OLAP 系统(Redshift、BigQuery、ClickHouse),它持有数据的反规范化副本。绝不直接对 OLTP 分片跑分析。
- 激进反规范化——在多个分片存数据的冗余副本以支持本地读。例如在每个订单分片存一份用户名,这样"带用户名的订单"查询无需跨分片用户 join。
- 维护全局二级索引——一个把非分片键字段映射到分片位置的单独索引分片。增加写复杂度(必须保持索引同步)但避免了索引查找的 scatter-gather。
跨分片事务:最难的问题
跨多个分片的 ACID 事务是分布式系统中最难的问题之一。两种标准方式及其取舍:
- 两阶段提交(2PC)——一个协调者请求所有参与分片准备(阶段 1)再提交(阶段 2)。保证原子性。问题:协调者在阶段 1 和阶段 2 之间持有所有参与分片的锁。若协调者在两阶段间崩溃,分片被留在不确定状态,无限期阻塞("阻塞问题")。还造成性能瓶颈:所有跨分片范围的事务都通过协调者串行化。
- Saga 模式——把事务分解成一系列本地单分片事务,每个发布一个触发下一步的事件。补偿事务在失败时撤销已完成步骤。Saga 是最终一致,而非原子一致——有一个系统处于部分提交状态的窗口。适合业务事务(电商结账、转账)但不适合底层数据完整性约束。
避免跨分片事务最干净的方法是设计你的分片,让每个关键事务只触及一个分片。这通常意味着共置参与同一事务的相关数据。对电商平台,把订单和购物车数据都按 user_id 分片,意味着结账事务(读购物车、写订单)对给定用户是单分片。
分片 vs. 复制:正交的关注点
分片和复制常被混淆,但解决完全不同的问题:
| 维度 | 分片 | 复制 |
|---|---|---|
| 解决什么 | 超过单节点的写吞吐和数据集大小 | 读吞吐、高可用和容错 |
| 数据分布 | 每行恰好存在于一个分片(无重复) | 每行存在于多个副本(全量重复) |
| 节点故障影响 | 丢一个分片 = 那部分数据不可用 | 丢主 = 副本提升;无数据丢失 |
| 读可扩展性 | N 个分片 × 各 1 主 = N 个并行写+读主 | 把读扇到副本;主只处理写 |
| 它们互斥吗? | 不——组合它们。每个分片本身应被复制:4 分片集群各 3 副本 = 共 12 节点。 | |
一个生产分片系统总是组合两者:分片实现写可扩展性和数据集分区、复制实现读可扩展性和高可用。没有复制,丢一个分片节点会让你整整一个数据分区不可用。没有分片,单个被复制的主在数据增长时成为写瓶颈。
跨分片的 Schema 变更
DDL 操作(加列、加索引、改数据类型)必须应用到每个分片——常是 8、16 或 64 个相同的 schema 变更,每个都需要在不锁生产流量的情况下运行。所需的运维纪律:
- 在线 schema 变更工具——
gh-ost(GitHub)和pt-online-schema-change(Percona)通过影子表加触发器的方式应用 DDL,从不取全表锁。对百万行表必不可少。 - 向后兼容的迁移——总是分两阶段做 schema 变更:先部署能处理新旧两种 schema 的代码,再应用 DDL,再移除处理旧 schema 的代码。这允许在任何步骤回滚而无 schema 不一致。
- 逐分片滚动——一次对一个分片应用 DDL 并监控错误再继续。一个分片上的坏迁移可在影响其他之前被停下。
- 自动化不可妥协——手动 SSH 进 64 个分片跑
ALTER TABLE不是一个流程。构建系统性地把变更应用到所有分片的 schema 迁移工具,带每分片成功/失败跟踪和自动回滚。
真实世界的分片架构
Vitess(YouTube / PlanetScale)
Vitess 是一个围绕 MySQL 构建的分片中间件层,在标准 MySQL 之上加连接池、查询路由和水平分片。它最初由 YouTube 构建以处理数十亿行视频元数据。Vitess 引入一个叫 VShard(逻辑分片)的概念,可重映射到物理 MySQL 实例而无需应用代码变更。路由层自动处理 scatter-gather、跨分片聚合和分片感知的 SQL 重写。PlanetScale 把 Vitess 作为托管服务提供。
Cassandra 的内建分片
Cassandra 是一个内部用带虚拟节点一致性哈希的分布式数据库——分片内建在存储引擎里,而非在应用层外挂。数据按分区键分区,同分区键的行共置(这些叫 wide row 或 clustering column)。一个设计良好的 Cassandra 数据模型让分区键与最常见访问模式对齐,并保持分区大小可控(~100 MB 以内)。Cassandra 的优势——线性写可扩展、无主节点、可调一致性——使它很适合高写、已知访问模式的负载,如消息系统、IoT 时序和活动 feed。
DynamoDB 的透明分片
DynamoDB 基于你预置或按需的容量设置自动分片——分片拓扑对应用不可见。你设计一个分区键(hash key)和可选的排序键(range key),DynamoDB 把请求路由到正确的内部分片。约束是单个分区键不能超过 10 GB 存储或 3,000 RCU / 1,000 WCU——违反它会造成节流请求的热分区。
只在你耗尽垂直扩展、读副本和缓存之后才分片——增加的运维复杂度真实且永久。当你确实分片,在分片键设计上重投入:高基数、写均匀分布、与最常见查询模式对齐。用带虚拟节点的一致性哈希最小化拓扑变化时的数据移动。接受跨分片查询和事务昂贵,并设计你的数据模型让它们罕见。并记住:每个分片需要自己的复制——分片和复制是正交、互补的工具。
哈希 vs 范围分片——何时选哪个?跨多 key 的写均匀分布用哈希(user_id、device_id);需要高效时间窗或连续键扫描且能容忍热点风险(或通过哈希前缀路由写来分散它们)时用范围。
一致性哈希为什么比取模分片好?取模哈希加节点重映射 ~(N-1)/N 的所有 key(几乎一切);一致性哈希只把 ~k/n 个 key 移到新节点,最小化数据迁移并允许在线重分片而最小中断。
什么是坏分片键?低基数(布尔、枚举)、哈希分片下的单调递增值(时间戳、自增),或与查询模式不对齐的键——都造成热点或迫使昂贵的 scatter-gather 扇出。
怎么处理跨分片事务?设计上优先把相关事务数据共置在同一分片。无法避免时,用 Saga 模式(带补偿动作的最终一致)而非 2PC(造成阻塞和协调者瓶颈)。
分片和复制的区别是什么?分片把不同行分散到节点以实现写可扩展;复制把相同行拷到多节点以实现读可扩展和 HA。生产系统两者都需要——每个分片本身被复制。