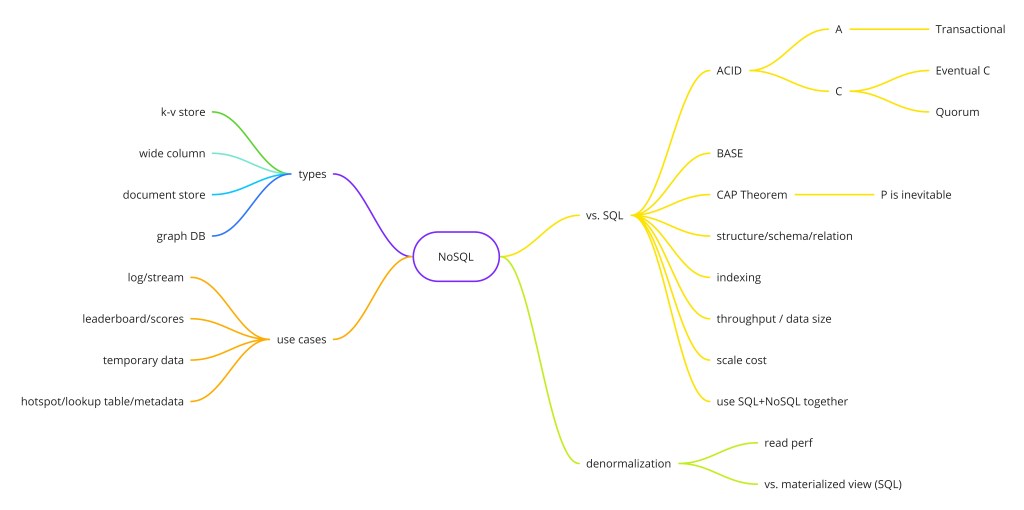
NoSQL("Not Only SQL")是一大类数据库系统,放弃关系表模型以换取灵活 schema、横向扩展和为特定访问模式调优的数据模型。它们诞生于 web 规模公司在海量读写吞吐和快速演化的 schema 下撞上关系数据库的极限之时。Google 2006 年发表 Bigtable,Amazon 2007 年发表 Dynamo,一个行业由此诞生。今天 NoSQL 涵盖四种根本不同的数据模型——键值、文档、列族、图——各解决一类不同问题。理解哪个模型适合哪种负载、以及为什么,是区分高级工程师的存储决策与初级工程师抛硬币的所在。
- 键值(Key-value)——按精确 key 做 O(1) 读写;无 schema、无查询;适合会话、缓存、限流。
- 文档(Document)——自描述 JSON/BSON;灵活 schema、无 join 的嵌套对象;适合用户资料、目录。
- 列族(Column-family)——行按 row key 索引,列按 family 分组并存;适合时序和高写分析负载。
- 图(Graph)——节点和边的原生遍历;适合社交图、推荐、欺诈检测。
- CAP 定理——分区容错强制必需;真正的选择是 CP(HBase、ZooKeeper)vs AP(Cassandra、最终模式的 DynamoDB)。
- 默认用 SQL;只在有专门数据模型能解决的特定瓶颈时才动用 NoSQL。
NoSQL 数据库用关系特性(join、严格 ACID)换 schema 灵活性和横向扩展。为你的数据模型选对类型:嵌套对象用文档,高吞吐查找用键值,时序和分析用列族,关系遍历用图。CAP 定理规定网络分区期间你必须在一致性和可用性间选择。
四大 NoSQL 类别
键值存储——速度层
最简单的数据模型:每个值存在一个唯一 key 下。按 key 读写是 O(1)——字面上一次哈希表查找。没有查询语言、没有 schema、没有关系——只有精确查找的纯速度。值本身对存储完全不透明;它可以是字符串、序列化对象、二进制 blob 或计数器。数据库不解释它。
- 示例:Redis、DynamoDB(KV 模式)、Memcached
- 最适合:会话存储、缓存层、限流计数器、特性开关、排行榜(配 Redis 有序集合)、分布式锁
- 局限:只能按精确 key 访问数据;无额外基础设施则无范围扫描;除非数据库把它作为单独功能层加上,否则无二级索引
Redis 值得特别关注,因为它远超简单 KV 存储。它的数据结构——字符串、列表、集合、有序集合、哈希、流、HyperLogLog——让你实现精巧的模式,如滑动窗口限流(对时间戳 ZRANGEBYSCORE)、pub/sub 扇出、排行榜(ZADD/ZRANK),以及通过 SET key value NX PX ttl 原子条件写实现的分布式锁。关键洞见是 Redis 在单线程事件循环里原子地执行所有操作,消除了困扰多线程进程内缓存的并发 bug。
# 带 TTL 的会话存储
SET session:abc123 '{"userId":42,"role":"admin"}' EX 3600
# 限流器:每用户 100 req/分钟的滑动窗口
ZADD ratelimit:user42 1716550000.123 "req:a1b2"
ZREMRANGEBYSCORE ratelimit:user42 -inf 1716549940.000 # 修剪旧条目
ZCARD ratelimit:user42 # 计数窗口内剩余
# 分布式锁——原子 compare-and-set
SET lock:order-42 "owner-xyz" NX PX 30000 # 仅当 key 不存在时成功文档存储——schema 灵活层
数据存为自描述文档(通常 JSON 或 BSON)。一个文档可包含嵌套对象和数组,无需 join 就表示一个完整实体。schema 灵活——同一集合的不同文档可有不同字段。这不是弱点;它是刻意的设计选择。当你的数据模型真正异构(一个商品目录里笔记本有 CPU/RAM 规格、T 恤有尺码/颜色变体)时,把一切塞进规范化关系 schema 要么产生一片可空列森林,要么产生可怕的 entity-attribute-value 反模式。
- 示例:MongoDB、Couchbase、Firestore
- 最适合:用户资料、商品目录、内容管理,任何数据天然层级化且 schema 频繁演化的领域
- 局限:反规范化数据意味着更新必须在多处应用;多文档事务可行(MongoDB 4.0+ 支持)但昂贵——它们作为安全网存在,而非主要模式
// MongoDB:插入并查询一个文档
await db.collection('users').insertOne({
_id: 'u-123',
name: 'Alice',
email: 'alice@example.com',
address: { city: 'Seattle', zip: '98101' }, // 嵌套对象,无需 join
tags: ['admin', 'beta']
});
const user = await db.collection('users').findOne(
{ 'address.city': 'Seattle' } // 查询嵌套字段
);
// DynamoDB:单表设计模式——所有实体类型在一张表
// PK = "USER#alice" SK = "PROFILE" → 用户记录
// PK = "USER#alice" SK = "ORDER#2024-01-15" → 订单记录
// 支持单次查询取出 用户 + 近期订单
const result = await ddb.query({
TableName: 'AppTable',
KeyConditionExpression: 'PK = :pk AND begins_with(SK, :prefix)',
ExpressionAttributeValues: { ':pk': 'USER#alice', ':prefix': 'ORDER#' }
});DynamoDB 在这里值得一提。尽管被当作 KV 存储营销,它的复合键模型(分区键 + 排序键)配 GSI 和 LSI 使它成为面向访问模式设计的强大文档存储。单表设计模式——把所有实体类型存在一张表、通过排序键前缀共置相关记录——让你在单次查询里满足多个访问模式,以前期建模严格性为代价完全消除 join。
列族存储——写扩展层
数据组织成由 row key 标识的行,列分组进列族(column family)。同一 family 内的列在磁盘上一起存储,使读大量行的一小组列极其高效——经典的分析访问模式。行可有不同列,新列无需 schema 迁移就能添加。关键设计洞见:主键(在 Cassandra 里是分区键 + 聚簇键)完全决定数据存在哪、哪些查询高效。你围绕查询模式而非规范化实体设计表。
- 示例:Apache Cassandra、HBase、Google Bigtable、ScyllaDB
- 最适合:时序数据(IoT 传感器、指标)、事件日志、排行榜、点击流和用户活动 feed 等写多负载
- 局限:查询模式必须建进表设计——你实质围绕查询反规范化;跨不同分区键的临时查询需要全扫描或二级索引,代价高
-- Cassandra:时序传感器读数
-- 分区键: sensor_id(一个分区 = 一个传感器的数据)
-- 聚簇键: ts DESC(分区内最新优先)
CREATE TABLE sensor_readings (
sensor_id UUID,
ts TIMESTAMP,
value DOUBLE,
unit TEXT,
PRIMARY KEY (sensor_id, ts)
) WITH CLUSTERING ORDER BY (ts DESC);
-- 取一个传感器最近 100 条读数:单分区,无 scatter
SELECT * FROM sensor_readings
WHERE sensor_id = 550e8400-e29b-41d4-a716-446655440000
LIMIT 100;
-- Cassandra 写路径:写进 commit log + memtable
-- 然后周期性刷到磁盘上不可变的 SSTable
-- → 无论数据量多大都是 O(1) 写Cassandra 的写路径解释了它为何能维持每秒数百万写:每次写追加到内存 memtable 和顺序 commit log,然后 memtable 周期性刷到不可变 SSTable。没有原地更新、没有锁、写时无索引维护。代价在 compaction 时付。这种 LSM-tree 架构(Log-Structured Merge-tree)也被 RocksDB、LevelDB、HBase 使用——它是列族存储主导写多负载的根本原因。
图数据库——关系层
数据建模为节点(实体)和边(关系),两者都有属性。图遍历——"找住在纽约、也买了商品 X 的朋友的朋友"——是原生一等操作,无需昂贵的多级 join 就能实现。关系数据库里同样的查询需要在好友表上多次自连接,性能随深度多项式退化。图数据库里,每个节点直接存指向其相邻边的指针——遍历是每跳 O(度),与图总大小无关。
- 示例:Neo4j、Amazon Neptune、ArangoDB、TigerGraph
- 最适合:社交网络、推荐引擎、欺诈检测(交易图)、知识图谱、网络拓扑
- 局限:不适合大批量表格数据;横向分片比其他 NoSQL 类型更难,因为跨分区切图造成跨分片遍历开销;大多数图 DB 最好跑在单台强力节点或小集群上
// Neo4j Cypher:找尚非好友的二度连接
MATCH (me:Person {id: 'alice'})-[:FRIENDS_WITH]->(friend)
-[:FRIENDS_WITH]->(fof)
WHERE fof.id <> 'alice'
AND NOT (me)-[:FRIENDS_WITH]->(fof)
RETURN fof.name, count(*) AS mutual_friends
ORDER BY mutual_friends DESC
LIMIT 10;
// 欺诈检测:找账号间共享的标识符
MATCH (a:Account)-[:USES]->(device:Device)<-[:USES]-(b:Account)
WHERE a.id <> b.id
RETURN a.id, b.id, device.fingerprint AS shared_deviceCAP 定理——分布式系统约束
CAP 定理由 Eric Brewer 提出、Gilbert 和 Lynch 形式化,陈述一个分布式数据存储只能同时保证以下三个属性中的两个:
| 属性 | 含义 |
|---|---|
| 一致性 (C) | 每次读返回最新的写或一个错误。所有节点同时看到相同数据。这是线性一致性——一个强安全保证。 |
| 可用性 (A) | 每个请求收到非错误响应,即便它可能不是最新数据。系统从不拒绝服务。 |
| 分区容错 (P) | 即便网络分区阻止某些节点通信,系统仍继续运作。节点间消息可能丢失或延迟。 |
网络分区在任何分布式系统中不可避免——交换机故障、机架掉电、跨数据中心链路退化。所以 P 实际上是强制的。真正的选择在 CP(分区期间牺牲可用性——返回错误而非陈旧数据;HBase、ZooKeeper)和 AP(牺牲一致性——服务陈旧数据而非报错;Cassandra、最终一致模式的 DynamoDB)之间。大多数 NoSQL 数据库让你通过一致性级别按操作调这个。
CAP 只描述网络分区期间的行为。PACELC 扩展它:即便没有分区,延迟和一致性之间仍有取舍。DynamoDB 的"最终一致读"更快,因为它们能从任何副本服务;"强一致读"必须路由到主并等它确认没有更新的写存在。真实生产系统在 PACELC 轴上调优的频率远高于 CAP 轴,因为分区罕见但延迟/一致性取舍持续存在。
深入一致性模型
CAP 二元的"C 或 A"框架对生产决策太粗。真实系统提供一个一致性保证谱系,理解它们让你按操作而非按数据库选对级别:
- 线性一致性(强一致)——每个操作看似在单个时间点原子执行。写后任何读返回该写。最安全、最昂贵的模型。用于金融账本、库存计数。Cassandra 里:
QUORUM读配QUORUM写(过半副本必须响应)。 - 因果一致性——若操作 A 因果上先于 B(你写了一个帖子,然后它的回复被写),任何看到 B 的读也看到 A。捕获 happens-before 关系而无需全局排序。用于协作工具(Google Docs 内部模型)。比线性一致更可用,比最终一致更正确。
- 最终一致性——若没有新写发生,所有副本最终收敛到同一值。无时间保证。读可能返回陈旧数据。适合社交媒体点赞、DNS、缓存。Cassandra 里:
ONE一致性级别意味着只需一个副本响应——最大吞吐、最大陈旧风险。 - 读己之写(Read-Your-Writes)——用户总能看到自己的写,即便其他用户可能看到陈旧数据。对任何交互式 UI 关键——若你发了评论并立即刷新,它应可见。Cassandra 里通过把读路由到同一协调者或用粘性会话实现。
- 单调读(Monotonic Reads)——一旦客户端读到值 X,后续读永不返回比 X 更旧的。防止值看似回退的"幽灵更新"体验。通过把读固定到一个副本实现。
-- 3 副本集群的 Cassandra 一致性级别
-- (RF=3,所以 QUORUM = 必须 2 个副本响应)
-- 强一致:W=QUORUM + R=QUORUM 保证无陈旧读
INSERT INTO orders (id, status) VALUES (42, 'PAID') USING CONSISTENCY QUORUM;
SELECT * FROM orders WHERE id = 42 CONSISTENCY QUORUM;
-- 最大吞吐:W=ANY + R=ONE — 最快但最陈旧
INSERT INTO page_views (url, ts) VALUES ('/home', now()) USING CONSISTENCY ANY;
SELECT count FROM page_view_totals WHERE url = '/home' CONSISTENCY ONE;BASE vs. ACID——正确性取舍
关系数据库由 ACID 保证定义。NoSQL 数据库通常转而提供 BASE 语义。理解这个取舍是选存储层的基础:
| 属性 | ACID (SQL) | BASE (NoSQL) |
|---|---|---|
| 原子性 | 事务里所有操作全成或全败——无部分状态 | 单实体操作原子;多实体操作可能留下可见的部分状态 |
| 一致性 | 数据库从一个有效状态移到另一个;约束被强制 | 基本可用(Basically Available)——系统即便有故障也推进 |
| 隔离性 | 并发事务看似串行执行 | 软状态(Soft state)——数据可能无显式写就随时间改变(TTL 过期、compaction) |
| 持久性 | 已提交数据挺过崩溃(WAL/journal) | 最终一致(Eventually Consistent)——副本收敛而无需同步达成一致 |
实际后果:对任何部分写会造成语义错误的领域用 SQL 和 ACID——金融账本、库存计数、订单记录。对临时不一致可接受的领域用 BASE 语义——社交 feed、读缓存、分析计数器、推荐分数。工程师犯的错误是假设所有数据都落入一类。在真实系统里,你几乎总是两者都需要:一个关系数据库存事务真相,一个或多个 NoSQL 存储处理特定高吞吐或高规模负载。
数据建模方法
文档存储建模——嵌入 vs 引用
文档存储的核心设计决策是把相关数据嵌入文档内,还是用外键等价物引用它。经验法则遵循"one-to-squiggly"准则:若相关实体基数有界且总与父一起访问,嵌入它。若它基数无界或有时被独立访问,引用它。
- 嵌入:博客帖子嵌入其标签、商品嵌入其变体列表、用户嵌入其最近地址——都有界、总一起读。
- 引用:博客帖子的评论(无界增长)、用户的完整订单历史(独立访问)、商品的卖家(独立访问)——无界或独立访问。
反模式:嵌入无界增长的数组。一个嵌入它所有评论的订单文档最终会撞上 MongoDB 16 MB 文档大小限制,并拖慢该订单的每次读取,即便不需要评论。通过问"这个数组永远增长吗?"来检测它。若是,改用引用。
列族建模——围绕查询设计表
在 Cassandra 里你不先规范化数据再写查询。你先写查询,再设计表来恰好服务那些查询。每张表是为一个特定访问模式优化的、数据的反规范化投影。"用户的活动 feed"和"所有 X 类型的活动"在 Cassandra 里需要两张独立的表,两者在每次写时都填充——一个写放大取舍,买到已知模式上的 O(1) 读。
-- 查询 1:"给我用户 alice 的 feed,最新优先"
CREATE TABLE user_feed_by_user (
user_id UUID,
created_at TIMESTAMP,
activity_id UUID,
type TEXT,
payload TEXT,
PRIMARY KEY (user_id, created_at, activity_id)
) WITH CLUSTERING ORDER BY (created_at DESC);
-- 查询 2:"全局显示所有 'purchase' 事件,最新优先"
CREATE TABLE activities_by_type (
type TEXT,
created_at TIMESTAMP,
user_id UUID,
payload TEXT,
PRIMARY KEY (type, created_at)
) WITH CLUSTERING ORDER BY (created_at DESC);
-- 写时:在应用里填充两张表代表性产品深入
DynamoDB——不计代价的托管扩展
DynamoDB 是 AWS 全托管、serverless 的 NoSQL 数据库。其定义性属性:任意规模个位数毫秒延迟、自动分片,以及基于预置或按需读/写容量单位的定价模型。其设计哲学——对访问模式高度强观点——强制前期建模纪律,在规模上回报丰厚。全局表提供带冲突解决的多区域 active-active 复制。DynamoDB Streams 能喂 CDC 管道。取舍:没有多表和应用侧 join 就无法做复杂查询;二级索引(GSI)是最终一致;跨分区事务存在(通过 TransactWriteItems)但昂贵且限于 100 项。
MongoDB——文档通才
MongoDB 是部署最广的文档数据库。它的聚合管道——一连串阶段,包括 $match、$group、$lookup(服务端 join)、$unwind 和 $project——覆盖了纯 KV 存储里需要多次查询的分析用例。Change Streams 支持 CDC 风格的管道。Atlas Search 在文档集合之上提供 Lucene 驱动的全文搜索。取舍:无 schema 集合若不通过应用级校验或 JSON Schema 约束施加纪律,会变成"无 schema 混乱";多文档 ACID 事务可用但应是例外而非规则;横向分片需要显式分片键规划,运维复杂。
Cassandra——写扩展冠军
Cassandra 由 Facebook 构建以支撑收件箱搜索功能,然后开源并被 Netflix、Apple 和 Discord(用它存数十亿消息)采用。它无主、点对点的架构(无主节点、无单点故障)意味着它能吸收节点故障甚至数据中心宕机而无停机。一致性哈希环把分区分散到节点,虚拟节点(vnode)概念把每个物理节点的 token 范围铺开,即便硬件异构也确保均匀分布。Discord 著名的"Cassandra 迁移"帖子记录了他们如何从 Cassandra 迁到 ScyllaDB(一个性能更好的无 JVM C++ 重实现)——值得一读,了解规模化列族存储的运维现实。
Neo4j——图标准
Neo4j 使用原生图存储格式,每个节点直接存指向其相邻边的指针,消除关系数据库做 join 所需的索引查找。它的 Cypher 查询语言对关系密集的查询可以说比 SQL 更可读。实际天花板:Neo4j 社区版是单节点;企业集群模型在数百亿节点和边以内工作良好,但跨机器分片一个属性图仍是个难研究问题。对真正巨大的图(Facebook 社交图),用自研方案或像 JanusGraph(在 Cassandra/HBase 之上)这样的专建系统。
CAP 实践:NoSQL 产品定位
| 数据库 | 类型 | CAP 定位 | 默认一致性 |
|---|---|---|---|
| Redis (cluster) | KV | CP — 主持有写;副本可能滞后 | 主上强;副本异步 |
| DynamoDB | KV / 文档 | AP(默认)/ CP(强读) | 最终;可选强 |
| MongoDB | 文档 | CP(主选举) | 默认主读;可调 |
| Cassandra | 列族 | AP(默认)/ CP(QUORUM) | 最终;按操作可调 |
| HBase | 列族 | CP — region server 故障时写阻塞 | 强(单个 region server 拥有范围) |
| Neo4j | 图 | CP(单主写) | 主上强;读副本异步 |
NoSQL vs. SQL:何时选哪个
| 场景 | 倾向 SQL | 倾向 NoSQL |
|---|---|---|
| Schema | 稳定、定义良好的关系 | 快速演化或每实体高度可变 |
| 事务 | 需要多表 ACID(金融、订单) | 单实体更新足够;BASE 可接受 |
| 查询模式 | 跨实体的灵活、临时 SQL 查询 | 前期设计的已知、重复访问模式 |
| 规模 | 中等——垂直扩展 + 读副本 | 海量——需横向写扩展(百万/秒) |
| 一致性 | 处处需要强一致 | 大多数读可接受最终一致 |
| 数据形状 | 表格、规范化、关系型 | 层级、类图、或时序 |
何时不该用 NoSQL
围绕 NoSQL 的炒作周期让许多团队过早放弃 SQL。以下是 NoSQL 错误选择的场景:
- 复杂多实体事务——若一个业务操作触及多个实体类型且必须全有或全无(如在两个银行账户间转 $100 并记录交易),SQL 的原生 ACID 事务比跨多个 NoSQL 存储编排分布式 Saga 更简单、更安全、更高性能。
- 重度临时分析——一张为"用户近期订单"设计的 Cassandra 表,无痛苦的二级索引或全扫描就无法回答"上月加州下单金额在 $50 到 $100 之间的所有订单"。SQL 的查询规划器优雅处理这个。
- 强关系约束——外键强制、级联删除、引用完整性是一等 SQL 特性。NoSQL 存储一个都不给你;你必须在应用代码里强制它们,而那里它们更不可靠。
- 带复杂查询的中小数据集——带恰当索引的 Postgres 轻松处理数亿行。为一个能住在调优良好的 Postgres 实例里的数据集动用 Cassandra,增加运维复杂度而无收益。
- 快速变化的访问模式——若你的查询模式频繁演化,Cassandra"围绕查询设计表"的哲学变成迁移噩梦。SQL 让你以后加索引;Cassandra 需要新表。
规模化的生产系统几乎从不用单一数据库类型。典型架构:PostgreSQL 做事务核心(订单、账户、用户),MongoDB 做灵活目录和内容,Cassandra 或 DynamoDB 做高写事件流和时序,Redis 做缓存和实时计数器,Elasticsearch 做全文搜索。每个 NoSQL 存储都是为解决一个特定瓶颈而加入的,而非取代关系核心。
性能与扩展模式
NoSQL 里的横向分片
大多数 NoSQL 数据库自动或半自动处理分片。理解机制在出问题时很重要。Cassandra 里,一致性哈希把分区键分散到环上——但选得差的分区键造成热分区,一个节点吸收不成比例的流量份额。基本规则:分区键应有高基数和均匀分布的写负载。在 Cassandra 用低基数键(如"国家代码")作分区键最多造几百个分区,峰值时让大多数节点闲着。
DynamoDB 里,热分区表现为特定 key 上的 "ProvisionedThroughputExceededException" 错误。缓解是分区键分片:给 key 追加随机后缀(1–N)、跨带后缀的变体分散写,并跨所有变体 scatter-gather 读。难看但对病态负载(爆款帖子上的全局点赞计数器)有效。
复制与冲突解决
多副本存储面对写冲突问题:对同一 key 在不同副本上的两个写在它们同步前发生。解决策略,从最简单到最正确:
- Last-Write-Wins (LWW)——时间戳较晚的写胜出。Cassandra 默认用。风险:时钟偏移意味着在慢时钟机器上晚 10ms 做的写可能被默默丢弃。对用户偏好这类最终一致数据可接受,对金融记录不可接受。
- 多值 / 兄弟解决——Riak(及某些 DynamoDB 配置)存两个冲突值并都返回给客户端,客户端必须显式合并。正确但复杂——客户端必须实现合并逻辑。
- CRDT(无冲突复制数据类型)——数学上保证无冲突合并的数据结构:G-Counter(只增)、PN-Counter(增/减)、LWW-Element-Set。Redis 和 Riak 为分布式计数器和集合等特定用例原生支持 CRDT。
NoSQL 不是关系数据库的替代——它是一套专门工具。从 SQL 开始;它把大多数用例处理得很好。在你有特定瓶颈时才动用 NoSQL:缓存速度查找用键值,灵活层级数据用文档,高写时序用列族,深度关系遍历用图。围绕你的访问模式建模数据,理解你运行在哪个一致性级别,并刻意决定在哪接受 BASE 而非 ACID。最好的工程师在同一系统里两者都用。
解释 CAP 定理及"P 是强制的"是什么意思。任何分布式系统里网络分区都会发生——所以你不能牺牲 P。真正的取舍是 CP(分区期间返回错误或阻塞以保持一致,如 HBase)vs AP(返回可能陈旧的数据以保持可用,如 Cassandra)。PACELC 扩展它:即便没有分区,也有日常更重要的持续延迟/一致性取舍。
什么时候选列族而非文档存储?当你写吞吐极高(百万/秒)、读模式前期已知、且你能负担围绕查询设计表时。Cassandra 的 LSM-tree 写路径让写无论数据量多大都 O(1)——文档存储在高量时付随机写代价。
为什么不能一切都用 NoSQL?NoSQL 用多表 ACID 事务和灵活临时查询换规模和 schema 灵活性。若你的领域有复杂关系且需要 join 或跨实体事务,SQL 几乎总是更简单、更安全、运维更便宜。过早加 NoSQL 增加运维复杂度而无瓶颈可解。
什么是最终一致性、何时危险?最终一致意味着副本会随时间收敛,但读在过渡期可能返回陈旧数据。它对库存计数(两个线程都读到 1 并写 0,导致负库存)、金融余额,以及任何陈旧读导致现实世界动作的场景危险。对这些用强一致(Cassandra 的 QUORUM、DynamoDB 的强一致读)——以更高延迟为代价。
DynamoDB 的单表设计模式是什么?把所有实体类型存在一张表,用复合排序键(如 ORDER#2024-01、PROFILE)共置相关记录,这样多个实体类型能在单次查询里取出而无 join。它需要前期访问模式分析,但为所有建模过的模式提供 O(1) 读。