A chat application sits at one of the most demanding intersections of system design: it must handle billions of users, hundreds of billions of messages per day, sub-second delivery latency, reliable offline queuing, and complex group semantics — all while maintaining end-to-end encryption and accurate presence information. The central challenge is that every message must be delivered to a specific device, not just a database record — which means the system must track live connection state across thousands of servers and route messages to exactly the right server in real time.
- WebSockets — persistent full-duplex connection eliminates polling lag; single connection per client enables true server-push.
- WebSocket Manager (Redis KV) — maps user_id → websocket_server:port; enables any service to route a message to the right server across 65K+ ports.
- Snowflake IDs — 64-bit: 41-bit ms timestamp + 10-bit machine ID + 12-bit sequence; distributed unique IDs with built-in time ordering for message display.
- Online vs. offline delivery — online: direct WebSocket delivery; offline: Pending status + push notification (APNs/FCM) until reconnect.
- Write fanout vs. read fanout — write fanout copies messages to each recipient's mailbox at send time; read fanout queries a shared message store at read time. Write fanout wins for small groups; read fanout wins for large ones.
- Group size cap — bounded fan-out cost (WeChat 500-user ceiling); each group message requires one delivery per member.
- Last seen sampling — poll presence ~1 min intervals; minor accuracy loss accepted to avoid write storm at 4B users.
Use WebSockets for full-duplex, persistent client-server connections. Route messages through a WebSocket Manager (key-value store) that maps user IDs to servers. Generate message IDs with Snowflake (time-ordered, distributed, 64-bit). Queue messages as "pending" for offline users and deliver via push notification. Use write fanout for 1:1 and small groups; switch to read fanout (shared message log) for large groups. Cap group size to bound worst-case fan-out cost.
Step 1 — Clarify Requirements
Chat applications range from simple 1:1 SMS-style messaging to real-time collaborative workspaces. Scope the problem before drawing any diagrams.
Functional
- User registration and authentication.
- One-to-one messaging with reliable delivery.
- Group chat (bounded size — e.g., 500 members max).
- Media support: text, images, audio, video clips.
- Read receipts (sent / delivered / read indicators).
- Last seen / online status tracking.
- Message history and search.
Non-Functional
- Low latency — real-time feel is the core product promise; <100 ms p99 delivery to online recipients.
- High availability — dropped connections or missed messages destroy trust; target 99.99%.
- Massive scale — 4 billion users, 100 billion messages daily.
- Message ordering — messages within a conversation must appear in send order on all devices.
- Exactly-once delivery guarantee at the application level — no duplicate messages, even on retry.
Step 2 — Capacity Estimation
WhatsApp / WeChat scale: 4 billion users, with roughly 1 billion daily active (DAU). Each DAU sends ~100 messages/day.
Message Volume
- 1B DAU × 100 messages/day = 100 billion messages/day.
- 100B ÷ 86,400 sec = ~1.15 million messages/sec average; with a 3× peak factor → ~3.5M msg/sec.
- Each message: ~1 KB average (including metadata) → 3.5M × 1 KB = ~3.5 GB/sec of message data at peak.
WebSocket Connections
- 1B DAU, each with one persistent WebSocket connection → 1 billion concurrent connections.
- A single server can handle ~100K concurrent WebSocket connections (each connection uses ~10 KB RAM for state) → 10,000 WebSocket servers needed.
- Each server listens on up to 65,535 ports; in practice connections are multiplexed on a single port per server so the limiting factor is RAM, not port count.
Storage
- 100B messages/day × 1 KB × 365 = ~36 PB/year of message data.
- Most users retain messages for years → messages are stored indefinitely per user expectation, tiered from hot (recent 90 days in Cassandra) to cold (older, compressed in object storage).
- Media attachments are the dominant storage cost: a 1 MB photo from 1% of messages = 1B media items/day × 1 MB ≈ 1 PB/day of media. Media is deduplicated by hash before storage.
Step 3 — API Design
# Auth
POST /api/auth/login
{ phone_number, otp }
→ { access_token, refresh_token }
# WebSocket connection (upgrade)
GET /ws/connect
Authorization: Bearer {access_token}
→ 101 Switching Protocols
Registers: user_id → ws_server:port in WebSocket Manager
# Send message (over WS frame, not REST)
-- Client sends WS frame:
{ type: "message", idempotency_key: "uuid",
receiver_id: 456, content: "hello", media_url: null }
-- Server replies:
{ type: "ack", message_id: 7234567890123, status: "sent" }
# REST: message history (pagination by cursor)
GET /api/conversations/{conv_id}/messages?before_id=7234567890123&limit=50
# REST: create group
POST /api/groups
{ name, member_ids: [1, 2, 3 ...] }
# REST: upload media (returns CDN URL)
POST /api/media/upload
Content-Type: multipart/form-data
→ { media_url, media_id }Message sending happens over the WebSocket connection, not via REST, because the connection is already open and adding REST round-trips would waste the persistent connection. The idempotency_key is client-generated (UUID) and prevents duplicate message creation on retry — if the client sends the same key twice (e.g., because the ACK was lost), the server returns the already-created message ID without creating a second message.
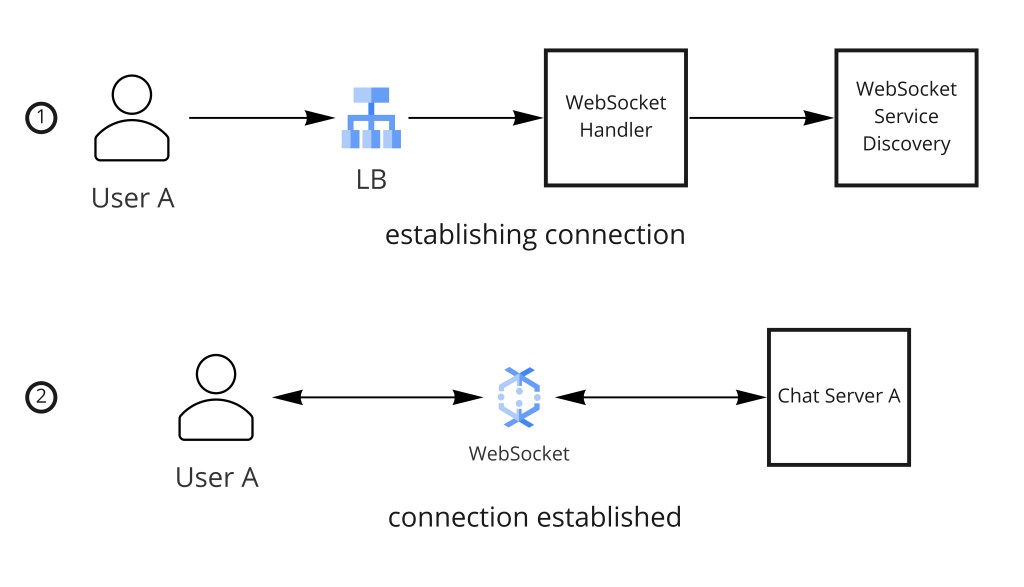
Step 4 — Protocol Selection: Why WebSockets
The central challenge of chat is server-to-client message push. Three approaches exist:
| Protocol | Problem |
|---|---|
| Short polling | Latency determined by poll interval; frequent polls waste resources, infrequent polls feel laggy |
| Long polling | Repeated connection setup/teardown overhead; multiple simultaneous requests can cause message ordering issues |
| WebSockets | Persistent full-duplex connection; eliminates polling overhead; supports true real-time bidirectional messaging |
| Server-Sent Events (SSE) | Server-push only; client cannot send over the same connection; still requires a separate HTTP channel for sends |
WebSockets win because they maintain a single persistent connection per client, enabling the server to push messages the instant they arrive with no polling lag and no connection re-establishment overhead. The connection stays open for the lifetime of the user's session; a heartbeat ping/pong every 30 seconds detects dead connections without requiring the client to poll.
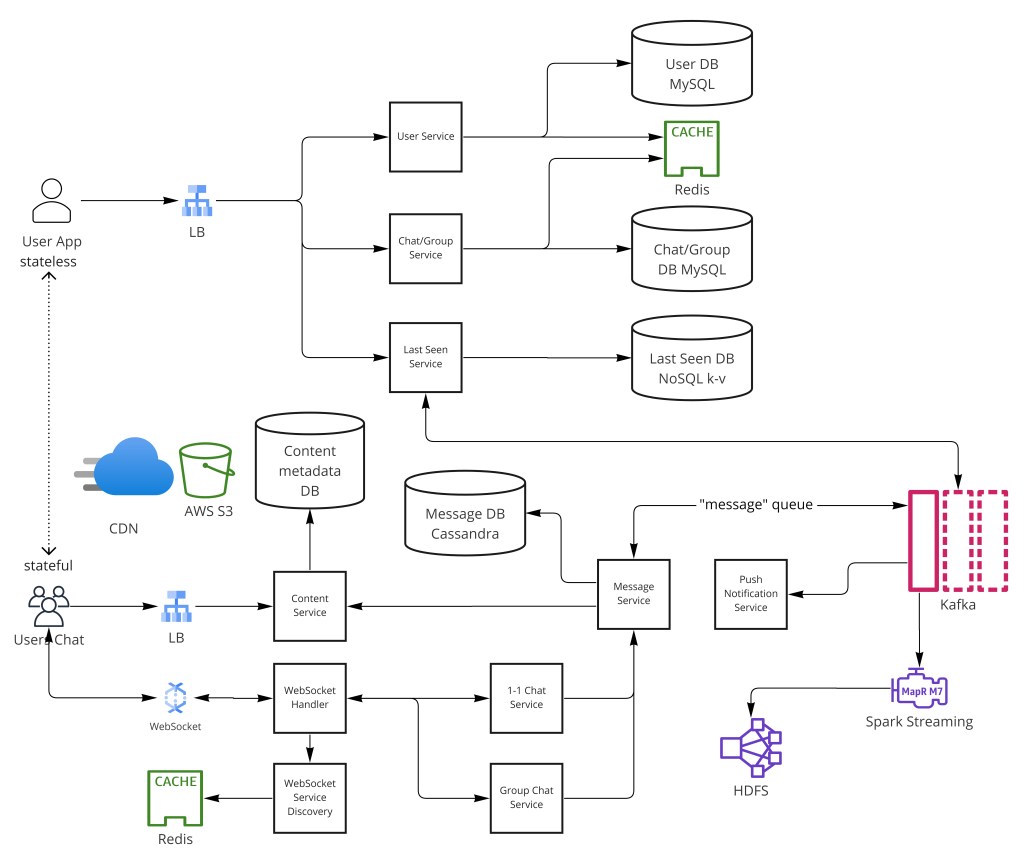
Step 5 — Core Services
- User Service — RESTful API for user CRUD, authentication, and contact management.
- Chat / Group Service — manages conversation creation, deletion, and group membership; stores
[group_id, member_list, admin_ids]. - Message Service — persists messages, generates Snowflake IDs, publishes events to Kafka for downstream processing.
- WebSocket Gateway — stateful servers that maintain long-lived client connections; handle WS frame parsing, heartbeats, and connection lifecycle.
- WebSocket Manager — maintains a key-value mapping of
user_id → websocket_server:port; backed by Redis for fast in-memory lookup. This is the routing table that lets any service find the right WebSocket server for any user. - Notification Service — dispatches push notifications (APNs for iOS, FCM for Android) to offline users.
- Presence Service — tracks online/offline status and last-seen timestamps.
- Media Service — receives binary uploads, stores in object storage, returns CDN URLs for embedding in messages.
Step 6 — Data Model
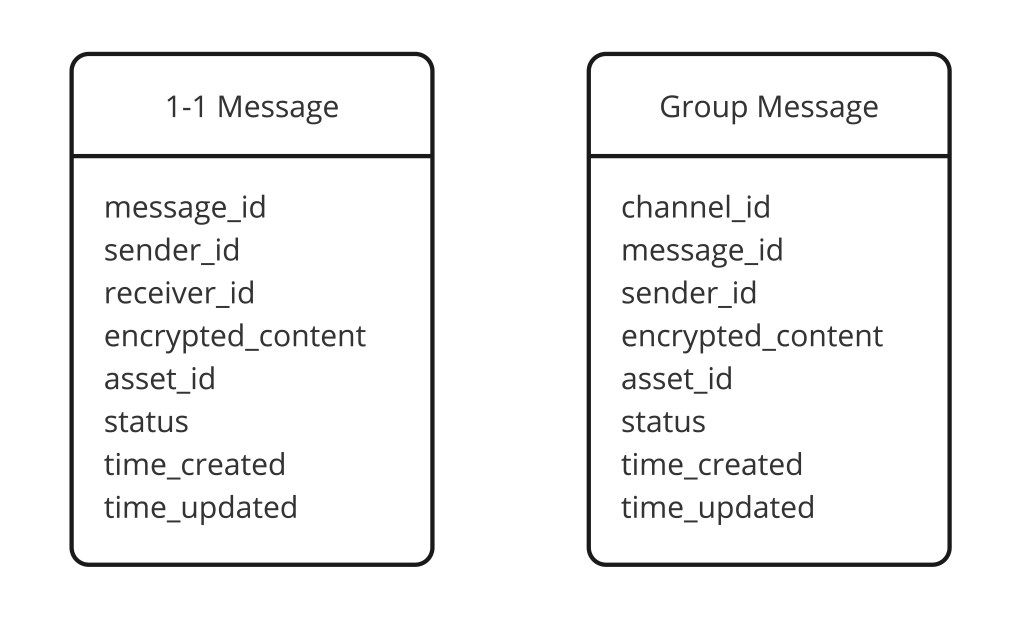
-- Messages table: partitioned by conversation for efficient history reads
CREATE TABLE messages (
conversation_id BIGINT,
message_id BIGINT, -- Snowflake ID (time-ordered)
sender_id BIGINT,
content TEXT, -- encrypted at rest
media_url TEXT, -- null for text-only
status ENUM, -- Sent | Delivered | Read
idempotency_key UUID, -- dedup on retry
created_at TIMESTAMP,
PRIMARY KEY ((conversation_id), message_id)
) WITH CLUSTERING ORDER BY (message_id DESC);
-- User inbox: each user's list of conversations with unread counts
CREATE TABLE user_inbox (
user_id BIGINT,
conversation_id BIGINT,
last_message_id BIGINT,
unread_count INT,
updated_at TIMESTAMP,
PRIMARY KEY (user_id, updated_at)
) WITH CLUSTERING ORDER BY (updated_at DESC);
-- Group membership
CREATE TABLE group_members (
group_id BIGINT,
user_id BIGINT,
role TEXT, -- member | admin
joined_at TIMESTAMP,
PRIMARY KEY (group_id, user_id)
);
-- Delivery receipts: per-message per-recipient status
CREATE TABLE receipts (
message_id BIGINT,
recipient_id BIGINT,
status TEXT, -- Delivered | Read
updated_at TIMESTAMP,
PRIMARY KEY (message_id, recipient_id)
);The messages table is partitioned by conversation_id so the most common query — "load the last 50 messages in this conversation" — is a single-partition scan. The clustering key message_id (a Snowflake ID) keeps messages ordered by time within the partition. Cassandra is the right storage here because the write pattern (high throughput, append-only) and read pattern (range scan within a partition, by time) map perfectly to Cassandra's strengths.
Step 7 — Message ID Generation: Snowflake
Message IDs must be globally unique, time-ordered (so messages sort correctly in the UI without a separate timestamp sort), and generated without coordination (so there is no single-point-of-failure ID generator). Snowflake IDs satisfy all three requirements:
Snowflake 64-bit ID layout:
┌─────────────────────────────┬──────────────┬──────────────────┐
│ 41 bits: ms timestamp │ 10-bit nodeID│ 12-bit sequence │
│ (epoch offset, ~69 years) │ (1024 nodes)│ (4096/ms/node) │
└─────────────────────────────┴──────────────┴──────────────────┘
Max throughput: 1024 nodes × 4096 IDs/ms = 4.19 million IDs/ms
Time ordering: IDs generated later are always numerically greater
No coordination: each node generates independentlyThe 41-bit timestamp field (milliseconds since a custom epoch) means IDs are sortable without a separate created_at field — comparing two Snowflake IDs directly tells you which message came first. The 10-bit node ID (configured per Message Service instance at startup) guarantees uniqueness across the fleet without any global lock or centralized ID service.
Step 8 — Message Delivery: Online vs. Offline
When a message is sent, the Message Service checks whether the recipient has an active WebSocket connection by querying the WebSocket Manager. Two paths diverge:
Sender sends message over WebSocket
→ WebSocket Gateway receives WS frame
→ Message Service:
1. Dedup check: idempotency_key in Redis (TTL 24h)
2. Generate Snowflake message_id
3. Persist to Cassandra (status: Sent)
4. Send ACK to sender: { message_id, status: "sent" }
5. Look up recipient in WebSocket Manager
[Recipient is ONLINE]
→ Forward to recipient's WebSocket server (via internal RPC)
→ WebSocket server pushes to client WS connection
→ Recipient client ACKs receipt
→ Message Service updates status: Delivered
→ Push Delivered receipt to sender via WS
[Recipient is OFFLINE]
→ Message stays in Cassandra (status: Pending)
→ Notification Service sends push notification (APNs/FCM)
→ On recipient reconnect:
Client sends { last_seen_message_id: 7234567890000 }
Server returns all messages with id > last_seen
Server updates status: Delivered
Sender receives Delivered receiptAt-Least-Once Delivery and Deduplication
The system guarantees at-least-once delivery at the network level — a message may be attempted multiple times on retries. The application layer must deduplicate to achieve the user-visible guarantee of exactly-once. The deduplication key is the client-supplied idempotency_key (UUID), stored in Redis with a 24-hour TTL. On retry, the Message Service checks Redis before writing to Cassandra; if the key exists, it returns the existing message ID without creating a duplicate.
Step 9 — Fan-out: Write Fanout vs. Read Fanout
Fan-out is the architectural decision that determines how messages get from a sender to all recipients. There are two fundamentally different approaches, each with different tradeoffs:
| Approach | How it works | Write cost | Read cost | Best for |
|---|---|---|---|---|
| Write fanout (push model) | At send time, copy the message into each recipient's mailbox / inbox | O(N) writes where N = recipients | O(1) per-user inbox scan | Small groups, DMs; N is bounded |
| Read fanout (pull model) | Store message once in a shared log; each recipient fetches on read | O(1) write | O(members) per read (each reader scans the shared log) | Large groups, public channels; write cost would explode |
Hybrid Strategy
Production systems (WhatsApp, Slack, Telegram) use a hybrid:
- 1:1 messages and small groups (<100 members) — write fanout: at send time, the Message Service writes one delivery record per recipient into their inbox. Each recipient's inbox scan is O(1) at read time. The write cost of ~100 writes is negligible.
- Large groups (>100 members) — read fanout: the message is stored once in a shared conversation log. When a member opens the conversation, they query the log with a cursor ("give me messages since my last-read position"). This avoids the O(5000) write cost of a 5,000-member channel.
- Very large public channels — read fanout with a separate "unread count" stored per-user as a simple integer, avoiding the need to scan the full message log to compute the badge count.
Write fanout trades write amplification for fast reads; read fanout trades write simplicity for read complexity. The crossover point is roughly 100–200 members: below that, write fanout wins; above that, read fanout avoids an O(N) write storm.
Step 10 — Group Chat and Ordering Guarantees
Group messages replace receiver_id with a conversation_id and must be delivered to all group members simultaneously. This fan-out is the main scalability challenge in group chat: a message to a 500-person group requires 500 individual delivery attempts. The design caps group size (WeChat's 500-user ceiling is the reference) to bound the maximum fan-out cost and delivery lag.
Message Ordering Within a Conversation
Two users sending messages simultaneously can both "win" and produce ordering conflicts. The solution is to use the Snowflake ID as the canonical ordering key — messages are always displayed sorted by message_id ascending. Since Snowflake IDs incorporate a millisecond timestamp, two messages sent within the same millisecond from different nodes are differentiated by the node ID bits, ensuring a deterministic total order even under concurrent sends.
For conversations where strict causal ordering matters (e.g., "reply to message X"), a reply_to_message_id field is included in the message schema. The client UI renders the thread view by following these links, regardless of the arrival order of the messages.
Step 11 — Read Receipts
The iconic double-tick / blue-tick indicators (sent → delivered → read) are a read receipt system. Implementation details:
- Sent — the sender's client gets an ACK from the Message Service with the assigned
message_id. One tick. - Delivered — the recipient's device receives the message and sends a delivery ACK back through the WebSocket. The Message Service updates the
receiptstable and pushes aDeliveredevent to the sender. Two ticks. - Read — the recipient's app marks the message as read (user opens the conversation). The client sends a
ReadReceiptframe over the WebSocket. Two blue ticks.
For group messages, the sender sees "delivered to all" only when every member has a Delivered receipt in the receipts table. This is O(members) reads per "delivered to all" check — the reason WhatsApp shows a per-member drill-down list rather than a single aggregate indicator for groups.
Batching Receipt Writes
At 100B messages/day, individual receipt writes would add another 200–300B writes/day to the database (two receipts per message). The Notification Service batches receipt updates: delivery ACKs are accumulated in Redis for 500 ms, then flushed to Cassandra in a single batch write. This reduces write amplification by ~50–100×.
Step 12 — Presence and Last Seen
Tracking "is this user online?" and "when did they last use the app?" sounds simple but is one of the hardest scalability problems in a chat system at 4 billion users.
Naive Approach and Why It Fails
The simplest implementation would have each user write their current timestamp to a database every second. At 1B DAU × 1 write/sec = 1 billion writes/sec — this is obviously impossible.
Presence via Heartbeat Sampling
The Presence Service uses a sampled approach:
- The WebSocket Gateway sends a heartbeat to the Presence Service every 60 seconds per active connection:
{ user_id, online: true }. - 1B active connections × 1 write/60 sec ≈ ~16.7M writes/sec — still very high, but manageable with a sharded Redis cluster.
- Each user's presence state is stored in Redis as a key with a TTL of 90 seconds. If no heartbeat arrives within the TTL, the key expires and the user is considered offline.
- "Last seen" timestamp is written to Cassandra only on disconnect or once per hour while online, not on every heartbeat. This reduces Cassandra write load by 3600×.
Presence Subscription (Contacts' Online Status)
Users want to know which of their contacts are online. The naive approach (query Presence Service for each contact on every page load) generates O(contacts) requests per user open. The production approach uses a pub-sub model:
- When user A comes online, the Presence Service publishes an
onlineevent to a channel keyed byuser_id_A. - Any WebSocket server that has a subscriber to user A's contact list (i.e., a friend of A is connected) receives the event and pushes it to that friend's WebSocket connection.
- Redis Pub/Sub or a dedicated presence broker (e.g., a lightweight MQTT broker) handles the fan-out.
Step 13 — Media Storage
Images, audio, and video are not stored inline in message objects. Instead, the message record holds a CDN URL, and the actual binary content lives in object storage. The upload flow:
- Client calls
POST /api/media/upload. - Media Service generates a pre-signed S3 upload URL and returns it along with a
media_id. - Client uploads directly to S3 via the pre-signed URL (bypasses application servers entirely).
- S3 triggers a Lambda/event that notifies the Media Service of upload completion.
- Media Service records the
media_id → CDN URLmapping and returns the CDN URL to the client. - Client includes the CDN URL in the message payload.
Media deduplication: before uploading, the client computes a SHA-256 hash of the file and sends it to the Media Service. If the hash already exists in the database (another user already uploaded the same file), the server returns the existing CDN URL without a new upload — zero bytes transferred for duplicates. This is especially effective for viral media (memes, voice notes) where the same file is shared by thousands of users.
Step 14 — Scaling and Fault Tolerance
WebSocket Server Scaling
- WebSocket servers are stateful (they hold open connections) but the routing state is externalized to the WebSocket Manager (Redis). Adding a new server requires only registering it with a load balancer — no state migration.
- On server crash, clients reconnect automatically (exponential backoff with jitter). The client sends its
last_seen_message_idon reconnect, and the server delivers all pending messages since that ID. - The WebSocket Manager's Redis entry for the crashed server is cleaned up by a health-check watchdog that removes stale entries when a server stops sending heartbeats.
Cassandra Sharding for Messages
- Messages are partitioned by
conversation_id. Cassandra distributes partitions across nodes using consistent hashing, so adding nodes redistributes load without a full reshard. - Hot conversations (a massive group chat) can cause a single partition to become a hot spot. Mitigation: bucket time within the partition key —
conversation_id + monthas a composite partition key, so message history is distributed across time-based buckets.
Message Queue and Replay
The Message Service publishes every incoming message to Kafka before persisting to Cassandra. This serves two purposes: it decouples the write path from downstream consumers (notification service, analytics, search indexer), and it enables replay — if a consumer falls behind or crashes, it can replay from its last committed Kafka offset without losing messages.
Key Tradeoffs
| Decision | Choice | Trade-off accepted |
|---|---|---|
| Real-time delivery | WebSocket (persistent) | Stateful servers; harder horizontal scaling than stateless HTTP |
| Message ID generation | Snowflake (distributed) | Node IDs must be assigned carefully; clock skew can cause rare ordering issues |
| Fan-out strategy | Hybrid (write <100, read >100) | Complexity of two code paths; threshold tuning required per platform |
| Message storage | Cassandra (partitioned by conv) | No cross-conversation queries; analytics must use a separate OLAP store |
| Presence tracking | Sampled heartbeat (60s) | Online status is slightly stale; "last seen 5 minutes ago" may be off by up to 60s |
| Delivery guarantee | At-least-once + client dedup | Client must handle and discard duplicates (idempotency_key check) |
Chat design is mostly about three hard problems: real-time delivery (WebSockets + WebSocket Manager for routing), offline queuing (Pending status + push notifications + catch-up on reconnect), and fan-out strategy (write fanout for small groups, read fanout for large ones). Snowflake IDs solve distributed unique ID generation with built-in time ordering. Group size caps are an explicit scalability lever. Presence sampling trades minor accuracy for write throughput — the classic availability-consistency tradeoff applied to a non-obvious dimension.
How do you route a message to the correct server when millions of WebSocket connections are spread across many servers? A WebSocket Manager (backed by Redis) stores user_id → server:port; any service can look up the target server in O(1) and forward the message via internal RPC.
Why cap group chat size? A group message fans out to every member — a 1,000-person group means 1,000 individual deliveries. Capping size bounds worst-case fan-out latency and prevents a single message from saturating the delivery pipeline.
What happens if a message is sent to an offline user? The message is stored with status Pending; a push notification (APNs/FCM) wakes the recipient's device; on reconnect the client sends its last-seen ID, the server delivers all missed messages, and status is updated to Delivered.
Write fanout vs. read fanout — when do you use each? Write fanout copies to each inbox at send time (fast reads, O(N) writes) — use for DMs and small groups. Read fanout stores once in a shared log (O(1) write, O(members) reads) — use for large groups where write amplification would be prohibitive.
How do you prevent duplicate messages on retry? Client-generated idempotency keys (UUID) stored in Redis with a 24-hour TTL. The Message Service checks the key before writing; if it already exists, returns the existing message ID without creating a duplicate.