URL 短链是一个看似简单的服务:接收一个长 URL、返回一个短的、再把短的重定向回原始。表面看它像一个带查找的两列数据库。但设计挑战在规模上迅速复合:你必须在分布式机群上生成保证唯一的短 ID 而无全局锁、为全世界每次点击保持重定向延迟近零、在不出现读瓶颈的情况下处理 100:1 的读写比、支持自定义别名而不与自动生成的命名空间冲突、在不影响热路径性能的前提下清除过期链接,并在保持重定向路径快如 CDN 边缘响应的同时记录点击分析。每一个都是非平凡的系统设计决策,它们的相互作用造成微妙的正确性和性能陷阱。
- 6 字符 base-62 slug——62⁶ > 568 亿个唯一 slug;在此规模足够多年的 URL 量。
- ID 生成胜过哈希——Snowflake 或范围分配在源头避免冲突;MD5/SHA-1 前缀冲突需检测 + 重试循环。
- 布隆过滤器做冲突检查——Redis 布隆过滤器:阴性 = 一定是新的(可安全写);阳性 = 可能存在(回退到 DB 查找)。保持快路径便宜。
- 读上 Redis 缓存——吸收 100:1 读写比;大多数重定向从不命中数据库。
- 301 vs 302 是产品决策——301 在浏览器缓存(更少命中、无分析);302 每次都命中短链服务(完整分析、更高负载)。
- 自定义别名需要独立命名空间——用户提供的 slug 必须对照自动生成命名空间和自定义别名表检查以防冲突。
- 点击分析经异步管道——每次重定向把点击事件记到 Kafka;分析消费者异步聚合,不给热重定向路径加延迟。
6 字符 base-62 slug 为一年的 URL 量提供足够命名空间。用 ID 生成(Snowflake 或范围分配)而非哈希来避免冲突。加一个 Redis 布隆过滤器在写前检查已存在的 slug。在 Redis 缓存热重定向。通过 TTL、定时扫描或惰性求值清除过期 URL。对写端点限流以防 DDoS。把点击事件流到 Kafka 做异步分析。
第 1 步 — 澄清需求
设计任何东西前,显式界定问题。URL 短链是常见面试题,因为它看似平凡却迅速暴露深度。问面试官这些维度:
功能需求
- 从一个长 URL 输入生成一个短 URL。
- 把短 URL 重定向回原始长 URL。
- 支持自定义别名(用户提供的短码,如
tiny.url/my-brand)。 - 给链接设过期日期/TTL;过期链接返回 404。
- 跟踪点击分析:总点击、唯一访客、referrer、国家、设备类型。
- 用户账户管理自己的链接(可选,但常见于产品型面试变体)。
非功能需求
- 极低重定向延迟——重定向在互联网上每次点击发生;目标全球 <50 ms p99。
- 极高可用性——服务宕掉会破坏现存的每个短链;目标 99.99%。
- 唯一性保证——两个不同长 URL 绝不能映射到同一短码;一个短码必须总解析到恰好一个长 URL。
- 可扩展性——处理 10M DAU、10:1 读写比;在大规模扩展到 100:1。
显式问点击分析是否必需——答案驱动你的重定向策略。若是,你大概想要 302 重定向(无浏览器缓存)和一个分析管道。若否,301 + 激进 CDN 缓存更简单更便宜。陈述你的选择和理由。
第 2 步 — 容量估算
粗略估算锚定存储和基础设施决策。假设一个中型部署、10M DAU。
流量
- 写速率:假设每 DAU 每天创建 ~0.1 个短 URL → 10M × 0.1 = 1M 写/天 ≈ 12 写/秒平均;峰值 ~2–3× → ~30 写/秒。
- 读速率:假设每个 URL 平均每天被点击 ~10 次 → 1M × 10 = 10M 重定向/天 ≈ 115 读/秒平均;峰值 5–10× → ~1,000 读/秒。
- 读写比在此规模 ≈ 10:1;在大型病毒链接规模(一个热门链接被点击数百万次)它轻易达到 100:1 或更高。
存储
- 每条 URL 记录:~100 字节(slug 6 B、长 URL ~100 B 均、created_at 8 B、expires_at 8 B、user_id 8 B)≈ ~130 字节/记录。
- 1M 新 URL/天 × 365 天 × 130 字节 ≈ ~47 GB/年 URL 记录——轻易装进单个 SQL 数据库,更别说分片的。
- 分析事件:若我们记录每次点击(115 读/秒 × 86,400 s × ~200 字节)≈ ~2 GB/天点击事件;这些去时序存储或数仓,而非热 URL 数据库。
Slug 命名空间定容
- Base-62 字符集:
[0-9, a-z, A-Z]= 62 字符。 - 6 字符 slug:62⁶ = 56,800,235,584 个唯一码——超过 568 亿。
- 每天 1M 新 URL,这个命名空间持续超过 155,000 年。即便每天 1B URL 也持续 ~56 年。6 字符是经典答案。
- 7 字符给 62⁷ = 3.5 万亿——若你真预期十亿每天的规模才用。
存储数学展示了为什么 URL 短链是个常被误解的"难"问题:数据量很小。真正的挑战是分布式写规模下的唯一性保证、读规模下的重定向延迟,以及自定义别名命名空间的正确性——而非原始存储。
第 3 步 — API 设计
干净、最小的 REST 面。整个服务本质是两个端点加一个管理层:
# 写:创建一个短 URL
POST /api/shorten
Authorization: Bearer <token>
{ "long_url": "https://example.com/very/long/path?q=1",
"custom_alias": "my-brand", // 可选
"expires_at": "2025-12-31" } // 可选
→ 201 { "short_url": "https://tiny.url/aB3kPq",
"slug": "aB3kPq", "expires_at": "2025-12-31" }
# 读:重定向
GET /{slug}
→ 302 Location: https://example.com/very/long/path?q=1
→ 404 若 slug 未找到或过期
# 分析:某链接的点击统计
GET /api/links/{slug}/analytics
Authorization: Bearer <token> // 必须拥有该链接
→ { "total_clicks": 14827, "unique_visitors": 9301,
"clicks_by_country": {...}, "clicks_by_day": [...] }
# 管理:删除一个链接
DELETE /api/links/{slug}
Authorization: Bearer <token>POST /api/shorten 端点对同一 (long_url, custom_alias) 对幂等——两次提交同一请求返回已存在的 slug 而非创建重复。按用户 token 对此端点限流:免费层可能允许 10 创建/分钟,付费层 100/分钟。GET /{slug} 重定向端点在热路径上;它必须尽可能快,且对读者从不限流(只有写侧需要保护)。
第 4 步 — 短 ID 生成:哈希 vs ID 生成
核心问题是如何生成 6 字符 slug。有四种主要方法,各有独特取舍:
| 方法 | 机制 | 冲突风险 | 可排序 |
|---|---|---|---|
| MD5 / SHA-1 哈希 | 哈希长 URL,取 base-62 编码前 6 字符 | 高——生日悖论在 568 亿空间用短前缀时咬人 | 否 |
| UUID(随机) | 生成随机 128 位 UUID,base-62 编码前 6 字符 | 低但非零——需要冲突检测 | 否 |
| Snowflake ID | 41 位时间戳 + 10 位机器 ID + 12 位序列;base-62 编码 | 机器 ID 唯一则为零 | 是(时间有序) |
| 范围分配 | 中央控制器给 worker 节点分配数字范围;worker 用范围内下一个值 | 零 | 是 |
为什么哈希有问题
哈希长 URL 并取前 6 字符看似优雅——同一 URL 总产生同一 slug(确定性)、无需协调。问题是生日悖论:在 568 亿槽位空间,插入大约 √(2 × 56B) ≈ 334,000 个 URL 后,冲突概率超过 50%。每天 1M URL,你不到一天就撞上。每次冲突都需检测(DB 查找或布隆过滤器检查)和带 salt 的重试——现在你在写路径上有一个延迟不确定的重试循环。
Snowflake ID 生成
Twitter 的 Snowflake 格式从打包进单个整数的三个组件生成 64 位 ID:一个 41 位毫秒时间戳(从 epoch 给 ~69 年余量)、一个 10 位机器 ID(支持 1,024 个唯一生成器节点)和一个 12 位序列计数器(允许每机器每毫秒 4,096 个 ID)。把这个 64 位整数转 base-62 给最多 11 字符——对 6 字符 slug,取低 36 位(base-62 编码到 62⁶ ≈ 56B 的数需要 ~36 位)。
import time
EPOCH = 1700000000000 # 自定义 epoch ms
MACHINE_ID = 1 # 部署时分配(0–1023)
BASE62 = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
_seq = 0
def generate_snowflake():
global _seq
ts = int(time.time() * 1000) - EPOCH
_seq = (_seq + 1) & 0xFFF # 12 位回绕
return (ts << 22) | (MACHINE_ID << 12) | _seq
def to_base62(n: int, length=6) -> str:
chars = []
while n > 0:
chars.append(BASE62[n % 62])
n //= 62
return "".join(reversed(chars)).zfill(length)[-length:]
def new_slug() -> str:
return to_base62(generate_snowflake())范围分配(基于计数器)
Snowflake 的替代:一个中央协调器(如 ZooKeeper 节点或一个 SQL AUTO_INCREMENT 支撑的专用计数器服务)给 worker 节点分配数字范围。Worker 1 拿 0–999,999;worker 2 拿 1,000,000–1,999,999,等等。每个 worker 把它的下一个计数器值转 base-62 并用作 slug。范围内无需协调——worker 自增一个本地计数器。范围耗尽时,worker 向协调器请求新范围。这个方法比 Snowflake 简单且无冲突,但造成一个必须高可用的单点协调器。
对大多数面试场景,Snowflake 是首选答案:它在 ID 生成层无需协调(每个节点给定预分配机器 ID 后独立生成 ID)、时间有序(对调试和分析有用)、且构造上无冲突。范围分配是有效替代——若面试官问更简单的设置则偏好它。
第 5 步 — 布隆过滤器做冲突检测
即便用无冲突 ID 生成,你仍需为基于哈希的方法和自定义别名(用户提供的字符串,可能与自动生成 slug 或彼此冲突)做冲突检测。经典工具是 Redis 布隆过滤器。
布隆过滤器是一个概率数据结构,回答"这个元素一定不在集合里吗?"或"这个元素可能在集合里吗?"。它从不产生假阴性但可能产生假阳性。操作规则:
- 布隆过滤器说否(位未设)→ slug 一定是新的——可安全写,无需 DB 查找。
- 布隆过滤器说是(位已设)→ slug 可能存在——回退到 DB 查找确认。若 DB 说它存在,用新 slug 或 salt 重试。
这让写快路径——压倒性常见情况(新 slug)——成为一次 O(1) 内存 Redis 检查而非 DB 往返。假阳性率(由过滤器位数组大小和哈希数控制)通常配到 1% 或更低,意味只有 100 次写中 1 次承担不必要的 DB 查找。
单个 Redis 布隆过滤器在高规模成瓶颈。把布隆过滤器检查分散到多个 Redis 实例减少瓶颈但牺牲单一真相来源——一个极致规模下无干净解的已知取舍。一个替代是完全跳过布隆过滤器、用 Snowflake ID(构造上无冲突),只在 DB 里检查自定义别名。
第 6 步 — 数据模型
URL 存储简单,但 schema 细节对正确性和查询性能要紧:
CREATE TABLE urls (
slug VARCHAR(8) PRIMARY KEY, -- 短码(6–8 字符)
long_url TEXT NOT NULL,
user_id BIGINT, -- 匿名则 NULL
is_custom BOOLEAN DEFAULT FALSE, -- 用户提供的别名
created_at TIMESTAMP NOT NULL,
expires_at TIMESTAMP, -- NULL = 永不过期
click_count BIGINT DEFAULT 0 -- 近似,异步自增
);
CREATE INDEX idx_user_id ON urls(user_id); -- 列出用户的链接
CREATE INDEX idx_expires ON urls(expires_at) -- 清除过期行
WHERE expires_at IS NOT NULL;
-- 分析事件(高量,写到 Kafka → OLAP 存储)
-- 不存在热 SQL DB 里
-- Kafka 消息 schema:
-- { slug, timestamp_ms, ip, user_agent, referrer, country, device_type }关键 schema 决策:slug 是主键——每个重定向是主键查找,在 B-tree 索引上 O(log n)、极快。expires_at 部分索引(过滤到非 NULL 行)保持清除扫描便宜。click_count 列是近似计数器——它由分析消费者异步自增,不在重定向热路径上,所以它可能滞后几分钟但从不阻塞重定向。
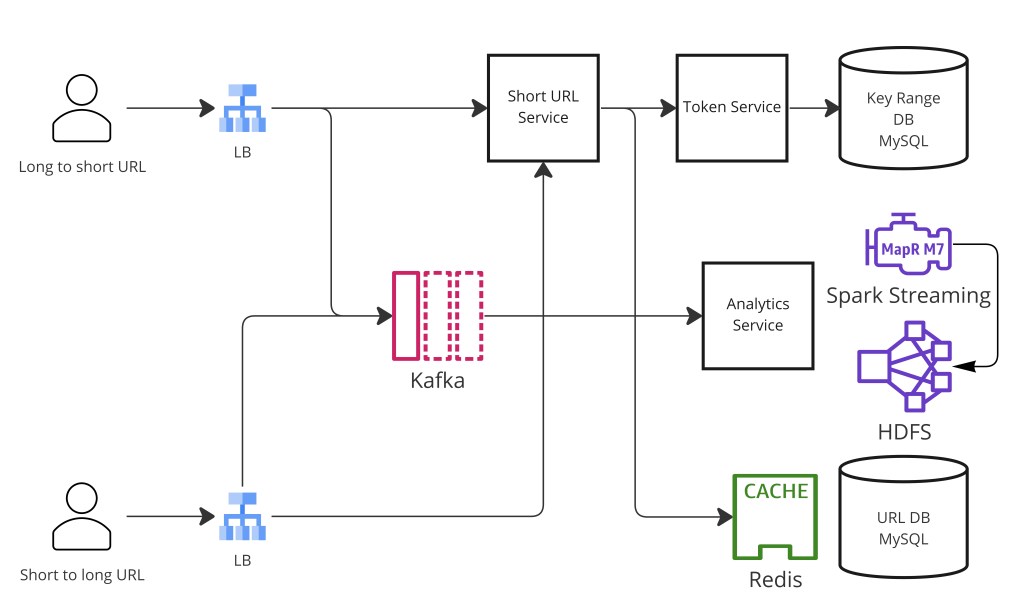
第 7 步 — 核心架构与读/写路径
-- 写路径(短化一个 URL)
POST /api/shorten { long_url, custom_alias?, expires_at? }
→ 限流器(按 user_id 或 IP 的令牌桶)
→ 若提供 custom_alias:
检查别名未被占用(DB 查找)
slug = custom_alias
否则:
slug = to_base62(snowflake_id())
→ 检查 Redis 布隆过滤器(仅哈希方法)
阴性 → 可安全写
阳性 → DB 查找确认;冲突则重试
→ 把 { slug, long_url, user_id, expires_at } 写到主 DB
→ 把 slug 加进布隆过滤器(若使用)
→ 把 slug → long_url 加进 Redis 缓存(TTL = min(expires_at, 24h))
→ 返回 { short_url: "https://tiny.url/{slug}" }
-- 读路径(重定向)
GET /{slug}
→ 检查 Redis 缓存
命中 → 检查 expires_at → 302/404 重定向
未命中 → 按主键 DB 查找
找到 → 缓存 → 302 重定向
未找到 → 404
→ fire-and-forget:发布点击事件到 Kafka
{ slug, ts, ip, user_agent, referrer, country }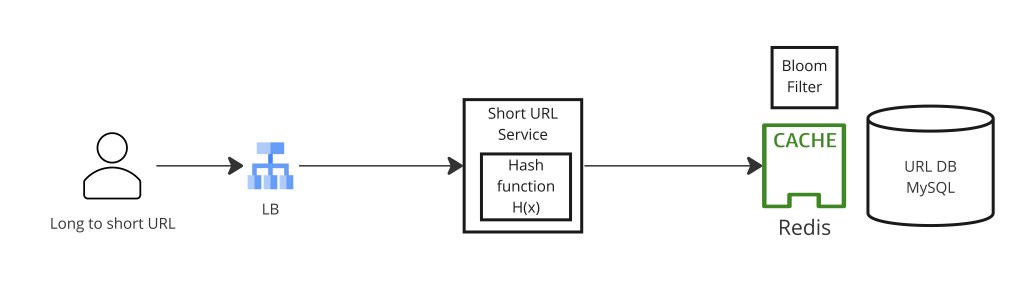
深入 Redis 缓存
100:1 读写比下,缓存是杠杆最高的单项优化。缓存模式是look-aside 配 write-through:写时立即填充缓存,使第一次重定向已是缓存命中;读未命中时从 DB 拉并填充。关键缓存决策:
- TTL——设为
min(链接 expires_at, 24 小时)。明天过期的链接不该被缓存过它的过期。不过期的链接得 24h TTL 配急切刷新,以避免热门链接上的 stampede。 - 热点链接——名人分享的病毒链接能在几分钟内收到数百万点击,打爆一个 Redis 分片。用 进程内本地缓存(重定向服务里的 LRU 缓存,1 s TTL)在 Redis 前缓解,或把热 key 跨多个 Redis 节点复制。
- 缓存击穿——当热门链接的缓存条目过期,数千重定向请求同时未命中并猛敲 DB。用一个单飞互斥(single-flight mutex):只有一个请求重建缓存条目;其他等它。或用概率提前过期(基于链接的点击速度在 TTL 归零前刷新)。
- 缓存失效——链接被删除(经
DELETE /api/links/{slug})时,立即从缓存驱逐它。绝不从陈旧缓存服务一个已删除的链接。
第 8 步 — 重定向:301 vs 302
HTTP 重定向响应码是一个有重大系统设计含义的产品决策:
| 码 | 含义 | 浏览器行为 | 分析影响 | 服务器负载 |
|---|---|---|---|---|
| 301 | 永久重定向 | 在浏览器缓存;后续点击跳过短链服务 | 只记录首次点击 | 极低——浏览器处理重复访问 |
| 302 | 临时重定向 | 不缓存;每次点击都命中短链服务 | 每次点击都记录 | 更高——所有点击经过服务 |
若点击分析是产品需求,你必须用 302——301 意味短链服务在首次后从不再见同一浏览器的重复点击。若不需要分析、想要最低成本下的最大性能,301 + CDN 缓存是正确选择:CDN 边缘节点缓存 301 并以边缘延迟服务重复重定向,而不碰你的源服务器。
一些服务对前 N 次点击用 302 收集分析,然后在阈值后切到 301。这正确实现起来复杂(切换必须与缓存失效协调)但偶尔在高级面试里被问到。更简单:总用 302 但加一个 CDN 层,以短 TTL(如 60 s)缓存重定向,以减少源负载同时仍捕获大多数点击。
第 9 步 — 自定义别名
自定义别名(tiny.url/my-brand)是用户提供的字符串,不能与自动生成 slug 或其他用户的自定义别名冲突。命名空间管理规则:
- 校验——强制字符白名单(a-z、A-Z、0-9、连字符、下划线)、最小长度(3 字符)、最大长度(50 字符)。拒绝保留词(
api、admin、health等)。 - 唯一性检查——接受自定义别名前,检查
urls表:SELECT 1 FROM urls WHERE slug = :alias。若它存在且由另一用户拥有,用 409 Conflict 拒绝。若它存在且由同一用户拥有(幂等重提),返回已存在记录。 - 命名空间隔离——把自定义别名和自动生成 slug 存在同一
urls表,由is_custom标志区分。主键检查自动防止两个命名空间间的冲突。 - 自定义别名限制——免费账户可能允许 5 个自定义别名;付费账户无限。在 API 层强制,而非 DB。
第 10 步 — 点击分析管道
点击分析不能给重定向热路径加延迟。解法是一个 fire-and-forget 异步管道:
- 每次重定向,重定向服务异步(非阻塞)把点击事件发布到 Kafka。重定向本身立即返回。
- Kafka 消费者(分析 worker)消费事件流并写到为聚合查询优化的时序存储(ClickHouse、BigQuery 或 Redshift)。
- 一个单独的聚合作业(Spark 批或 Flink 流)预计算每链接 rollup:总点击、唯一 IP、按国家/设备/referrer 的点击、按小时/天的点击。
- 分析 API(
GET /api/links/{slug}/analytics)从预计算 rollup 存储读,而非从原始事件——O(1) 查找而非全扫描数十亿条点击记录。
重定向服务
└── fire-and-forget → Kafka topic: "click-events"
{ "slug": "aB3kPq", "ts": 1716556800000, "ip": "1.2.3.4",
"country": "US", "device": "mobile", "referrer": "twitter.com" }
分析消费者(Flink 流)
└── 读 Kafka → 按 (slug, hour, country, device) 计数
└── 把 rollup 写到 ClickHouse:
-- clicks_hourly(slug, hour, country, device, click_count)
分析 API
└── SELECT SUM(click_count) FROM clicks_hourly WHERE slug = 'aB3kPq'
→ 在 <10 ms 返回(索引 rollup 表)第 11 步 — URL 过期与清除
过期 URL 必须被清理以回收存储并返回正确的 404 响应。三种策略,各有不同取舍:
| 策略 | 怎么工作 | 优点 | 缺点 |
|---|---|---|---|
| Redis TTL | 给缓存条目设等于链接过期的 TTL;缓存自动驱逐 | 零 DB 开销;对缓存命中工作 | 过期行在 DB 累积;DB 仍显示记录存在 |
| 惰性求值 | 每次重定向检查 expires_at < NOW();返回 404 并可选删除 DB 行 | 无需批作业;自清理 | 过期行累积直到被访问;热路径上删除加延迟 |
| 定时扫描 | Airflow 作业每晚跑:用部分索引 DELETE FROM urls WHERE expires_at < NOW() | DB 保持干净;可预测负载 | 过期链接在 DB 里"有效"长达 24h;大表上批量删除可能慢 |
推荐方法组合全部三种:Redis TTL 为大多数流量正确处理缓存层;惰性过期检查在重定向处理器里捕获过期但别处缓存的链接的 DB 命中;每晚扫描保持 DB 表干净、部分索引小。惰性删除应异步做(如入队到删除队列)以保持重定向响应快。
第 12 步 — 扩展与容错
高规模时,URL 短链必须在硬件故障、流量峰值和区域宕机下保持可用和快。
读扩展
重定向服务是无状态的——它从 Redis、偶尔从 DB 读。在负载均衡器后横向扩展。有一个热 Redis 缓存吸收 95%+ 的读,DB 在最小负载下。给 DB 加读副本处理剩余缓存未命中。在多个区域部署重定向服务,用 CDN 或 GeoDNS 把用户路由到最近实例。
写扩展
~30 写/秒,单个 SQL 主库轻易处理 URL 创建。若写规模成关切(比如一个也提供经 API 编程式链接创建的平台,10,000 写/秒),按 slug 前缀分片 DB:以 0-9 开头的 slug 去分片 A,a-m 去分片 B,n-z 去分片 C。因为每个重定向是 slug 上的主键查找,路由到正确分片是一个简单字符映射——无需跨分片 join。
多区域一致性
一个全球分布的 URL 短链必须处理一个在 US-East 创建的链接立即被 Asia-Pacific 用户点击的情况。选项:
- 全局单区域主库 + 区域读副本——写去 US-East;EU 和 APAC 的副本在数秒内追上。重定向读命中本地副本。新创建的链接可能需 1–2 s 出现在 APAC——通常可接受。
- 多主配冲突检测——每个区域用 Snowflake ID 接受写(机器 ID 编码区域)。因为 Snowflake ID 构造上全局唯一,不可能有冲突。复制异步跨区域传播记录。
容错
- Redis 故障——若缓存集群宕,所有重定向落到 DB。设计 DB 容量以在 Redis 宕机期间(数分钟到数小时配自动恢复)处理 100% 重定向流量。带副本分片的 Redis Cluster 减少爆炸半径。
- DB 故障——自动故障转移到副本(如经 Amazon RDS Multi-AZ 或 PostgreSQL 的 Patroni)。故障转移期间短暂只读模式可接受;链接创建排队并重试。
- Kafka 故障——点击事件在此期间丢失。分析准确性退化但重定向不受影响(fire-and-forget 意味重定向不等 Kafka)。Kafka 本身以复制因子 ≥ 3 运行。
第 13 步 — 限流与安全
写端点必须用限流器保护,以防生成数百万 slug、耗尽存储和 slug 命名空间的 DDoS 攻击。安全层:
- 每用户令牌桶——已认证用户得到一个限流(如免费层 10 创建/分钟、付费 100/分钟)。在 Redis 用滑动窗口计数器实现:
INCR rate:user:{user_id}:{minute}+EXPIRE。 - 每 IP 限流——未认证请求(匿名短化)按 IP 限制以防未认证滥用。比每用户更宽松但作为兜底必要。
- URL 校验与恶意软件扫描——校验长 URL 是有效 URL(正则 + DNS 解析检查)。与恶意软件/钓鱼 URL 数据库(Google Safe Browsing API)集成,在创建一个会传播钓鱼链接的 slug 前拒绝已知恶意链接。
- 垃圾链接检测——对同一用户的同一长 URL 限流(创建 1,000 个全指向同一钓鱼页的 slug 是常见滥用模式)。
- 读端点对匿名用户不限流——重定向便宜且缓存吸收大部分负载。只在某特定 IP 做明显自动化量的重定向调用时才限流(bot 检测层)。
第 14 步 — 关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| Slug 生成 | Snowflake(基于 ID) | 需预分配机器 ID;轻微时间有序暴露创建量 |
| 重定向码 | 302(临时) | 比 301 更高服务器负载;若点击分析是产品功能则必需 |
| 冲突检测 | Redis 里的布隆过滤器 | 假阳性需 DB 回退;极致规模下过滤器本身需分布式 |
| 分析管道 | 异步(Kafka → OLAP) | 点击计数有短暂滞后;重定向延迟不受影响 |
| 过期强制 | 惰性 + 每晚扫描 | 过期链接在过期后可访问长达缓存 TTL(数秒);DB 在 24h 内清理 |
| 存储 | SQL(单表) | 轻易装下数据量;无需分布式 NoSQL 的复杂度 |
URL 短链设计是让无聊东西扩展的研究:Snowflake ID 生成胜过哈希(在源头避免冲突)、布隆过滤器使写路径上的冲突检查便宜、Redis 缓存吸收 100:1 读放大,而 slug 长度算术确认 6 字符足够数十年。微妙的选择——301 vs 302、哪种清除策略、用 Snowflake ID 时是否还用布隆过滤器——由产品需求而非技术约束驱动。了解取舍、陈述假设、为每个选择辩护。
为什么 slug 生成偏好 ID 生成而非哈希?哈希函数(MD5、SHA-1)因生日悖论能为不同 URL 产生同样的 6 字符前缀——冲突检测和重试增加复杂度和不确定延迟。Snowflake 或基于范围的 ID 生成在源头消除冲突。
布隆过滤器怎么加速冲突检测?布隆过滤器阴性(位未设)保证 slug 是新的——无需 DB 查找。只有阳性(罕见)需 DB 回退。这让写快路径在内存里 O(1)。
301 还是 302 重定向?301(永久)被浏览器缓存——更低服务器负载但首次访问后点击分析丢失。302(临时)每次点击都命中短链服务——完整分析但更高成本。基于分析是否产品需求选择。
怎么处理一小时内 10M 点击的病毒链接?Redis 里的热 key——跨多个分片缓存它,或在每个重定向服务实例加进程内 LRU 缓存(1–5 s TTL)在它命中 Redis 前吸收尖峰。
怎么防止分析管道拖慢重定向?fire-and-forget 发布到 Kafka——重定向立即返回 302 而不等 Kafka 写确认。Kafka 宕机期间丢失几个点击事件可接受;重定向可用性不可。