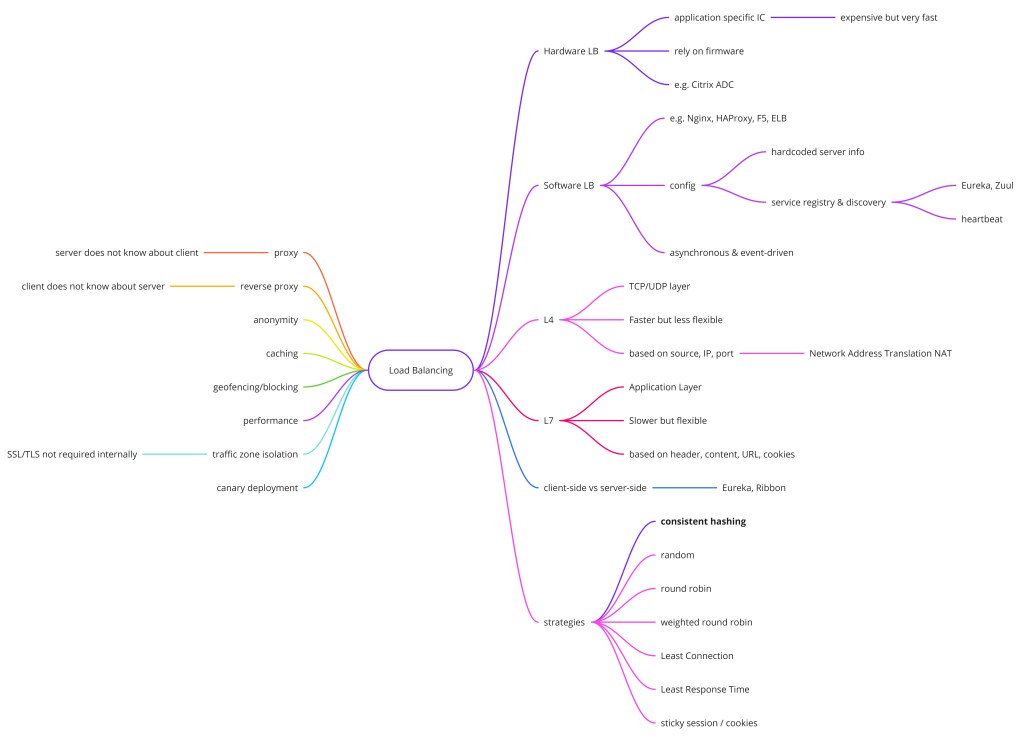
负载均衡器(load balancer)位于客户端和一组后端服务器之间,分发入站流量,让任何单台服务器都不会成为瓶颈。它是横向扩展的基石:加更多服务器,负载均衡器就自动分摊工作。没有它,横向扩展在运维上不可能,且单台服务器故障会拖垮整个服务。
- L4 vs L7——L4 按 TCP/UDP 头路由(快、不检查内容);L7 按 HTTP 路径/头/cookie 路由(更聪明、CPU 略高)。
- 轮询(Round Robin)适合均匀负载;最少连接(Least Connections)适应时长可变的请求。
- IP 哈希无需存状态就给出会话亲和性,但移除一台服务器时会重排所有客户端。
- 粘性会话是有状态服务器的权宜之计——真正的修法是把会话状态外置到 Redis。
- LB 冗余——用带 VIP 的 active-passive 或 active-active 对;LB 本身绝不能是 SPOF。
负载均衡器用轮询、最少连接或 IP 哈希等算法把流量路由到后端服务器。L4 LB 按 TCP/UDP 元数据路由;L7 LB 检查 HTTP 内容、能做更聪明的路由决策。健康检查自动把不健康的服务器移出池。
为什么要负载均衡?
它解决三个核心问题:
- 吞吐——一组较小服务器能处理的总请求比一台大服务器多,且增量扩展更便宜。
- 高可用——当一台服务器故障,负载均衡器通过健康检查检测到并停止向它路由流量,通常在数秒内。
- 降低延迟——地理负载均衡器能把用户路由到最近的数据中心,缩短往返时间。
第四层 vs. 第七层
| 维度 | 第四层(传输层) | 第七层(应用层) |
|---|---|---|
| 作用于 | TCP/UDP 头(IP + 端口) | HTTP 头、URL、cookie、body |
| 性能 | 非常快——不检查内容 | CPU 成本略高 |
| 路由智能 | 低——不感知应用协议 | 高——能按路径、host 或头值路由 |
| TLS 终止 | 仅透传 | 可终止 TLS、检查载荷、再加密 |
| 示例 | AWS NLB、HAProxy TCP 模式 | AWS ALB、Nginx、Envoy |
实践中,大多数现代架构在边缘用 L7 负载均衡器(做 HTTP 路由、TLS 终止、头操作),对内部 TCP 服务用 L4 负载均衡器——那里裸吞吐比路由智能更重要。
负载均衡算法
轮询(Round Robin)
请求按循环顺序依次分发到服务器池。当所有服务器容量相同、请求成本均匀时简单有效。加权轮询(Weighted Round Robin)扩展它:给每台服务器分配与其容量成比例的权重,权重 3 的服务器接收的请求是权重 1 的三倍。
最少连接(Least Connections)
每个新请求发给当前处理活跃连接最少的服务器。它自然适应请求时长可变的负载——处理长查询的服务器持有更少的新连接。加权最少连接在比较前先把活跃连接数除以服务器权重。
IP 哈希(IP Hash)
对客户端 IP 地址做哈希以确定性地选服务器。同一客户端总落到同一后端,提供会话亲和性而无需负载均衡器存会话状态。缺点:若移除一台服务器,它的所有客户端都被重新哈希和重分配,可能打断进行中的会话。
随机(Random)
均匀随机选一台服务器。在大请求量下统计上接近轮询,但小请求量无保证。当你想要零协调开销、且池大而同质时有用。
健康检查
负载均衡器定期探测后端以检测故障。一台服务器在连续失败可配置的次数后被标记为不健康并移出池;在连续通过可配置的次数后被重新加入。有两种口味:
- 被动健康检查——从实际流量推断健康。若服务器返回 5xx 错误,LB 标记它降级。
- 主动健康检查——LB 按计划发送合成探测请求(TCP 握手、对
/health的 HTTP GET),独立于真实流量。
upstream backend {
least_conn; # 最少连接算法
server 10.0.0.1:8080 weight=3;
server 10.0.0.2:8080 weight=1;
server 10.0.0.3:8080 backup; # 仅在主服务器全挂时使用
}
server {
listen 80;
location / {
proxy_pass http://backend;
proxy_next_upstream error timeout http_500;
}
}粘性会话(Sticky Sessions)
有些应用把会话状态存在服务器上(进程内缓存、进行中的文件上传)。粘性会话(也叫会话保持)确保某客户端的请求总去同一后端。负载均衡器通常通过在客户端首次请求时设 cookie、在后续请求读它来实现。
粘性会话是双刃剑:它改善与有状态应用的兼容性,但降低负载的均匀分布并使故障处理复杂化——若粘住的服务器宕机,它的所有会话反正都丢了。首选修法是把会话状态移到共享存储(Redis、数据库),让任何服务器都能处理任何请求。
负载均衡器冗余
负载均衡器本身是潜在的单点故障。生产部署用 active-passive 或 active-active 对,常配一个在节点间浮动的虚拟 IP(VIP)。DNS 或 BGP 把 VIP 路由到活跃节点;若它故障,被动节点通过 VRRP(HAProxy + Keepalived)等协议或更新 DNS 记录在数秒内接管 VIP。
一致性哈希(Consistent Hashing)
IP 哈希和简单的取模路由有一个灾难性缺陷:增删一台服务器几乎会重排所有客户端分配。若你有 10 台服务器加 1 台,模 11 对大多数 key 产生完全不同的目标——突然 90% 的缓存 key 在新服务器映射上未命中,在后端造成 thundering herd。一致性哈希通过把服务器和请求都映射到一个环形哈希环来解决:增删一台服务器只影响它与最近邻之间范围内的 key——对 n 台服务器大约 1/n 的 key。
环怎么工作
每台服务器被哈希到 0–2³²−1 环上的一个或多个点。每个请求 key 也被哈希到环上一个点;请求路由到从该点顺时针走遇到的第一台服务器。用虚拟节点(vnode),每台物理服务器占环上多个点(如每台 150 个 vnode),平滑掉服务器哈希聚集在环某一区域时的不均匀分布。
import hashlib, bisect
class ConsistentHashRing:
def __init__(self, nodes, vnodes=150):
self.ring = {} # hash → node
self.keys = [] # 排序的哈希值
for node in nodes:
for i in range(vnodes):
h = self._hash(f"{node}-{i}")
self.ring[h] = node
self.keys.append(h)
self.keys.sort()
def _hash(self, key):
return int(hashlib.md5(key.encode()).hexdigest(), 16)
def get_node(self, key):
h = self._hash(key)
idx = bisect.bisect(self.keys, h) % len(self.keys)
return self.ring[self.keys[idx]] # 顺时针后继一致性哈希被用于:分布式缓存(Memcached、Redis Cluster)、CDN 边缘服务器、数据库分片路由器,以及 Kafka 的分区分配。每当会话亲和性或缓存局部性重要、且你需要增删节点而不造成灾难性 key 重映射时,它就是答案。
L4 vs L7——更深入
高层区别众所周知,但实现细节决定每种场景该选哪个。
第四层的底层
L4 负载均衡器在 TCP/UDP 传输层工作。它看到源 IP、目的 IP、源端口、目的端口——别的什么都看不到。两种主流转发策略是:
- NAT 模式——LB 把目的 IP 改写成所选后端的 IP、把源 IP 改写成自己的地址,这样后端回复给 LB,再由 LB 翻译回去。简单但加一跳网络。
- 直接服务器返回(DSR)——LB 只改写目的 MAC 地址(或用隧道),让后端直接回复客户端,在返回路径上绕过 LB。响应流量(对 HTTP 通常是请求流量的 10–100 倍)从不经过 LB。这就是 Google 的 Maglev 和 Facebook 基于 IPVS 的 LB 实现每秒百万包吞吐的方式——让 LB 完全离开高流量返回路径。
第七层的底层
L7 负载均衡器终止来自客户端的 TCP 连接,读取 HTTP/gRPC/WebSocket 请求,基于内容做路由决策,再与后端建立一条独立的 TCP 连接。这种双连接模型使得 L4 无法提供的特性成为可能:
- 请求级路由——
POST /api/orders→ 订单服务;GET /api/products→ 商品服务。 - 头操作——加
X-Request-ID、改写Host、在发给后端前剥离内部头。 - TLS 终止——在 LB(或服务网格 sidecar)解密,检查明文,可选地重新加密到后端(TLS origination)。集中证书管理。
- 认证卸载——在 LB 校验 JWT 或 API key,只把已认证请求转发给后端。
- 限流和熔断——按客户端/API key 计数请求,在到达后端前拒绝超额。
- gRPC 负载均衡——L4 LB 无法在一条长连接的 HTTP/2 内均衡单个 gRPC 调用;只有理解 HTTP/2 帧的 L7 代理才能把调用分摊到后端。
gRPC 在单条长连接 HTTP/2 上多路复用许多调用。L4 负载均衡器把整条连接路由到一个后端——该连接上的所有调用都落到同一台服务器,彻底破坏了负载均衡。修法是用理解 HTTP/2 的 L7 代理(Envoy、带 gRPC 代理模块的 Nginx、Linkerd)把单个 gRPC 帧分摊到后端。
SSL/TLS 终止策略
负载均衡架构中处理 TLS 有三种标准方式,各有不同的安全/性能取舍:
| 策略 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 在 LB 终止 TLS | LB 解密流量;后端收到明文 HTTP | 集中证书管理;LB 能按内容检查/路由;后端更简单 | 内部流量不加密;LB 成了解密 oracle |
| TLS 透传(L4) | LB 转发加密字节;后端终止 TLS | 端到端加密;LB 从不见明文 | 无法做 L7 路由;每后端管理证书 |
| TLS 重加密 | LB 终止来自客户端的 TLS,再开一条新 TLS 连接到后端 | 两段都加密;LB 能检查和路由 | CPU 成本更高;要管两对证书 |
大多数云架构用边缘 LB 的 TLS 终止(AWS ALB、Cloudflare)结合内部 mTLS(服务间的双向 TLS,由 Istio 或 Linkerd 等服务网格强制)。这给你边缘的 L7 路由、集中的公网证书管理,以及端到端加密,而无需手工管理后端证书。
# TLS 终止 + 重加密到后端
server {
listen 443 ssl;
ssl_certificate /etc/ssl/certs/api.example.com.crt;
ssl_certificate_key /etc/ssl/private/api.example.com.key;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256;
location / {
proxy_pass https://backend; # 重加密到后端
proxy_ssl_verify on;
proxy_ssl_trusted_certificate /etc/ssl/certs/internal-ca.crt;
proxy_ssl_session_reuse on; # 复用 TLS 会话以提性能
}
}健康检查——高级配置
基础健康检查发一个 TCP SYN 或对 /health 的 HTTP GET。生产中,"进程还活着"和"进程能服务生产流量"之间的间隙正是大多数故障藏身之处。高级健康检查设计弥合这个间隙。
健康检查端点设计
设计良好的 /health 端点应检查所有关键依赖——数据库连通性、缓存可用性、下游服务可达性——并返回带每依赖状态的结构化 JSON。这让负载均衡器能区分"服务器彻底死了"(TCP 失败)和"服务器活着但数据库挂了"(HTTP 503),据此路由。
// GET /health/readiness — 就绪返回 200 OK,否则 503
{
"status": "degraded",
"checks": {
"database": { "status": "up", "latency_ms": 3 },
"cache": { "status": "up", "latency_ms": 0.5 },
"payment_gw":{ "status": "down", "latency_ms": 5000 }
}
}HAProxy 健康检查配置
backend api_servers
balance leastconn
option httpchk GET /health/readiness
http-check expect status 200
default-server inter 5s fall 3 rise 2 # 每 5s 检查;3 次失败=down,2 次成功=up
server api1 10.0.0.1:8080 check weight 10
server api2 10.0.0.2:8080 check weight 10
server api3 10.0.0.3:8080 check weight 5 # 小实例——权重减半
server api4 10.0.0.4:8080 check backup # 仅在所有主服务器全挂时激活DNS 负载均衡与全局流量管理
基于 DNS 的负载均衡完全在网络层之上工作:DNS 服务器给不同客户端返回不同的 A 记录,把它们分散到服务器池或地理区域。它是全局流量管理和多区域部署的基础。
DNS LB 怎么工作
你域名的权威 DNS 服务器根据策略返回不同 IP 地址——跨 IP 的简单轮询,或基于解析器 IP 的地理路由。客户端在 TTL 期间(常 30–300 秒)缓存响应,然后重新解析。这在 DNS 层、任何 TCP 连接建立之前,创造了天然的负载分布。
# 简单 DNS 轮询:连续查询返回不同 IP
api.example.com. 30 IN A 54.1.2.3 # US-East LB VIP
api.example.com. 30 IN A 52.4.5.6 # US-West LB VIP
api.example.com. 30 IN A 13.7.8.9 # EU-West LB VIP
# DNS TTL = 30s:客户端缓存 30s,然后重新解析到不同 IP
# 低 TTL 实现快速故障转移,但增加 DNS 查询负载DNS LB 的局限
- TTL 缓存——客户端和中间解析器在 TTL 期间缓存 DNS 响应。若一台服务器宕机,缓存了它 IP 的客户端会在最多 TTL 秒内一直尝试连接它,才拿到更新记录。设 TTL=0 有帮助但许多解析器忽略它。
- 无连接状态——DNS 对服务器负载、连接数或响应时间一无所知。活着但过载的服务器继续接收它那份流量。
- 默认粘性——长生命周期应用解析一次就把结果缓存在自己的连接池里。无论 TTL 如何,它们好几个小时都不会重新解析。
GeoDNS 与基于延迟的路由
AWS Route 53、Cloudflare、Akamai 等服务给 DNS 加上地理智能:它们识别解析器的位置(通常代理用户位置)并返回最近的健康端点 IP。欧洲用户把 api.example.com 解析到法兰克福 IP;新加坡用户解析到新加坡 IP。结合把不健康端点移出轮转的健康检查,GeoDNS 除了延迟优化还提供区域级故障转移。
Anycast 与全局负载均衡
Anycast 是一种路由技术:同一个 IP 地址通过 BGP 从多个地理位置同时通告。互联网的路由协议自然把包送到拓扑上最近的源——来自欧洲的流量到达欧洲 PoP,来自亚洲的到达亚洲 PoP,全都指向同一目的 IP。这就是 CDN 和 DDoS 清洗服务的工作方式:一个 IP 地址出现在数百个边缘位置。
Anycast 与 DNS LB 有一个重要区别:路由决策在网络层(BGP)做,不在应用层。没有 TTL 缓存问题——包在每一跳被路由到最近 PoP。而且因为 PoP 故障时 BGP 在数秒内重新收敛,故障转移比等 DNS TTL 过期更快更可靠。
Cloudflare 从全球 300+ 数据中心通告同一个 IP 地址(如其 DNS 解析器的 1.1.1.1,或其 CDN 的 anycast 网络)。东京用户连到东京边缘节点;圣保罗用户连到圣保罗边缘节点——全都指向同一 IP。这就是规模化的 Anycast:用单个 IP 地址实现全局负载分布和容错。
会话保持深入
粘性会话有几种实现变体,取舍差异显著。理解它们对生产运维和面试中讨论有状态应用都重要。
基于 Cookie 的亲和性
负载均衡器在客户端首次请求时设一个 cookie(如 SERVERID=api2)。后续请求,LB 读 cookie 并路由到指定后端。这是最常见且最灵活的方式——它跨 IP 变化也能工作(移动客户端切网络)、不暴露后端 IP,且 cookie TTL 控制亲和性持续多久。
backend web_servers
balance roundrobin
cookie SERVERID insert indirect nocache # LB 管理的粘性 cookie
server web1 10.0.0.1:80 check cookie web1
server web2 10.0.0.2:80 check cookie web2
server web3 10.0.0.3:80 check cookie web3IP 哈希亲和性
对客户端 IP 哈希以确定性选后端。无 cookie 开销,但在网络间漫游的移动客户端会被重分配,而企业客户端(许多用户在一个 NAT IP 后)全落到同一后端。增删服务器会改变与 1/n 成比例的客户端的哈希结果(假设一致性哈希)或几乎所有客户端(朴素取模)。
正确修法:外置会话状态
两种方式都是对一个更深层问题的权宜之计:会话状态存在应用服务器内存里。生产级解法是把会话状态移到共享、快速的存储如 Redis 或 Memcached。任何后端都能处理任何请求,因为会话从外部存储查,而非本地内存。这实现了真正弹性的横向扩展:增删服务器而无任何客户端可见的中断。
高可用与故障转移模式
本身有单点故障的负载均衡器解决了错误的问题。生产 LB 配置用两种高可用模式之一。
带 VIP 的 Active-Passive
两个负载均衡器节点共享一个虚拟 IP(VIP)。正常运行时,只有活跃节点占据 VIP 并处理所有流量。被动节点通过心跳(VRRP、keepalived)监视活跃节点。若活跃节点在可配置窗口内未发心跳,被动节点通过 gratuitous ARP 占据 VIP 并接管。故障转移通常在 1–2 秒内完成。AWS Elastic Load Balancer、Google Cloud LB、Azure Load Balancer 在内部管理这套——你从不见 VIP 机制。
# keepalived.conf(VRRP active-passive LB 对)
vrrp_instance VI_1 {
state MASTER # 被动节点设为 BACKUP
interface eth0
virtual_router_id 51
priority 110 # 优先级越高越优先做 master;BACKUP = 100
advert_int 1 # VRRP 心跳每 1s
authentication {
auth_type PASS
auth_pass secret123
}
virtual_ipaddress {
203.0.113.10 # 两节点竞争的 VIP
}
track_script {
chk_haproxy # haproxy 进程死掉则降级
}
}Active-Active
两个 LB 节点同时处理流量,通常通过两个 VIP 间的 DNS 轮询或上游 Anycast 地址。总吞吐翻倍。故障时,存活节点吸收所有流量。取舍:配置和状态同步稍复杂(若要 TCP 会话无缝挺过故障转移,连接表必须复制)。
算法对比与选择指南
| 算法 | 最适合 | 弱点 | 复杂度 |
|---|---|---|---|
| 轮询 | 请求成本均匀、服务器相同 | 请求时长不同或服务器容量不同则不均 | O(1) |
| 加权轮询 | 异构服务器容量 | 仍忽略当前负载;静态权重需手动调 | O(1) |
| 最少连接 | 请求时长可变(long-polling、流式) | 所有新连接同时发给一台空闲服务器(恢复时 thundering herd) | O(log n) |
| IP 哈希 | 无 cookie 开销的会话亲和性 | 增删服务器时重排;NAT 客户端造成热点 | O(1) |
| 一致性哈希 | 规模化的会话亲和性 + 缓存局部性 | 无 vnode 时分布略不均;实现更复杂 | O(log n) |
| 随机 | 无状态请求的超大同质池 | 小池无保证;不感知服务器负载 | O(1) |
| 最短响应时间 | 延迟敏感 API;按实际响应速度加权 | 需要主动测量开销;可能放大 thundering herd | O(log n) |
现代架构中的负载均衡
服务网格(Service Mesh)
在微服务架构中,服务网格(Istio、Linkerd、Consul Connect)把负载均衡逻辑从中心 LB 设备移到一个与每个应用 Pod 并行运行的 sidecar 代理(通常是 Envoy)。每个 sidecar 拦截所有入站和出站流量,应用负载均衡、重试、熔断和 mTLS——应用代码毫不知情。控制平面(Istio 的 istiod、Linkerd 的控制平面)把配置更新分发给所有 sidecar。
优势:在每个服务间调用都做带每请求路由决策的 L7 负载均衡,而非只在边缘。代价:每个 Pod 现在有一个消耗约 50–100 MB RAM、每跳加约 1–2 ms 延迟的 sidecar。
AWS Application Load Balancer——关键特性
- 基于内容的路由——按路径(
/api/*→ ECS 服务)、host 头、query string 或 HTTP 方法路由。 - 目标组加权——把 10% 流量发给新服务版本做金丝雀部署。
- Lambda 目标——把特定路径路由到 Lambda 函数,在一个 LB 后混合容器化和 serverless 后端。
- WebSocket 和 HTTP/2 支持——ALB 足够连接感知,能维持长连接 WebSocket 并分发 HTTP/2 流。
- WAF 集成——挂上 AWS WAF,在流量到达后端前在 LB 阻断常见攻击模式。
常见坑与最佳实践
- 永远别忘了 LB 是 SPOF——跑 active-passive 或 active-active 对。100 个高可用后端前的单个 LB,让整个架构的可用性不超过那个 LB。
- 健康检查要紧的东西,不只是 TCP 端口开着——进程可能在 8080 监听,而它的数据库连接池已耗尽。检查
/health/readiness,不只 TCP SYN。 - 设置连接排空(deregistration delay)——从池移除后端时,允许进行中的请求完成(通常 30–300 秒)再关闭连接。AWS ALB 叫它"deregistration delay";Nginx 用
proxy_next_upstream结合优雅关闭。 - DNS LB 的低 TTL 不等于即时故障转移——解析器忽略 TTL 下限,浏览器缓存,OS stub 解析器缓存。即便 30 秒 TTL,也要为 DNS 变更完全传播预留 60–120 秒。
- 监控后端队列深度,不只连接数——最少连接算法路由到连接最少的服务器,但处理慢的 30 秒 DB 查询的服务器比服务快速 50ms 请求的连接更少。对延迟敏感层,最短响应时间或队列深度指标更准确。
- 把健康检查流量与生产流量分开——每秒对 50 个后端猛敲
/health的吵闹健康检查产生 50 req/秒负载。用一个做最少工作的轻量端点,并把依赖检查结果缓存几秒。
需要路径路由、TLS 终止或头检查的 HTTP 负载选第七层。需要裸 TCP 吞吐、非 HTTP 协议或通过直接服务器返回获极致性能选第四层。按请求同质性选算法:均匀负载用轮询,可变负载用最少连接,缓存局部性和会话亲和性用一致性哈希。始终至少跑两个 active-passive 或 active-active 配置的负载均衡器,以免引入你本要消除的那个 SPOF。
L4 vs L7——何时选哪个?L4 用于裸 TCP 吞吐、非 HTTP 协议,或需要直接服务器返回让返回流量绕开 LB 时;L7 用于需要基于路径的路由、TLS 终止、gRPC 支持或基于头的决策时。
负载均衡器怎么检测故障服务器?主动健康检查(按计划对 /health 的合成探测)或被动健康检查(从真实流量的 5xx 错误率推断)。主动检查检测流量前故障;被动检查检测进行中故障。
粘性会话为什么是问题?它们降低负载分布、使扩展复杂化,并意味着该服务器宕机时所有会话数据都丢——修法是把会话状态外置到 Redis,让任何服务器处理任何请求。
一致性哈希是什么、何时用?把服务器和请求映射到环;增删服务器只影响约 1/n 的 key,而非重排一切。用于分布式缓存、CDN、数据库分片和 Kafka 分区分配。
Anycast 怎么工作?同一 IP 通过 BGP 从多个地理 PoP 通告;互联网路由自然把包送到拓扑最近的 PoP——无 DNS 解析、无 TTL 缓存、PoP 宕机时亚秒级故障转移。
L4 LB 为什么不能均衡 gRPC 流量?gRPC 在单条 HTTP/2 连接上多路复用许多调用;L4 LB 把整条连接路由到一个后端。只有理解 HTTP/2 帧的 L7 代理才能把单个调用分摊到后端。