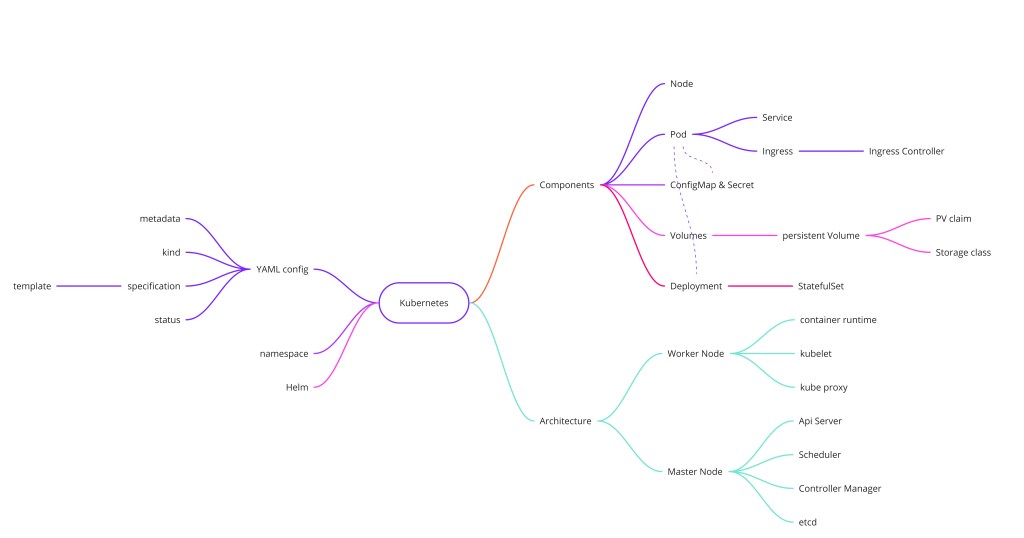
Kubernetes 是一个开源的容器编排平台,自动化容器化应用的部署、扩缩和管理。随着行业从单体服务转向微服务,需要一个能以高可用、可扩展、健壮方式运行独立、轻量应用容器的编排器——而这正是 Kubernetes 提供的。
- Pod——最小可部署单元;封装一个或多个容器,在集群内获得共享的虚拟 IP。
- Service——给 Pod 一个跨重启稳定的 IP/DNS 名;同时充当内部负载均衡器。
- 控制平面——API Server(唯一网关)、Scheduler(放置 Pod)、Controller Manager(协调循环)、etcd(真相来源)。
- Deployment vs StatefulSet——Deployment 给无状态应用;StatefulSet 给需要稳定有序身份的数据库。
- Secret 是 base64,不是加密——配合 HashiCorp Vault 或 KMS 做真正的密钥管理。
- Helm——Kubernetes 的包管理器;把 YAML 清单打包成有版本、可参数化的 Chart。
Kubernetes 把容器组织成 Pod,通过 Service 给它们分配稳定网络身份,并通过运行 API Server、Scheduler、Controller Manager 和 etcd 的 master 节点协调一切。worker 节点运行 Kubelet 和 Kube Proxy 来承载实际负载。
核心原语
Pod
Kubernetes 中的基本单元。Pod 是一个或多个容器之上的抽象层,让 Kubernetes 独立于底层容器运行时(Docker、containerd、CRI-O)。每个 Pod 获得一个供集群内通信的虚拟 IP,但只要 Pod 被替换这个 IP 就会变——这正是 Pod 需要在其上叠加一个稳定寻址机制的原因。
Service
Service 提供一个独立于 Pod 生命周期、保持不变的静态 IP 地址。当一个 Pod 死掉、新的启动时,Service 的 IP 保持固定,继续把流量路由到健康的 Pod。Service 还充当内部负载均衡器,把请求分摊到同一应用的多个副本上。
Ingress
Ingress 位于集群边界,行为像一个反向代理。它根据路由规则把外部域名(如 api.example.com)翻译成正确的内部 Service IP 和端口,这样你只暴露一个入口,而不是每个服务一个 NodePort。
ConfigMap 与 Secret
ConfigMap 把应用配置(环境变量、配置文件)外置,这样你无需重建容器镜像就能更新设置。Secret 镜像 ConfigMap,但存储敏感数据——凭证、API key、TLS 证书——以 base64 编码。两者都不应被当成安全保险箱;生产密钥管理请配合 HashiCorp Vault 等工具。
Volume
容器文件系统是临时的——Pod 重启时数据就消失。Volume 给 Pod 挂载持久存储(本地磁盘或远程块/对象存储),确保数据库这类有状态负载能在 Pod 替换后存活。
Deployment vs. StatefulSet
| 方面 | Deployment | StatefulSet |
|---|---|---|
| 用例 | 无状态应用(web 服务、API) | 有状态应用(数据库、消息代理) |
| Pod 身份 | 可互换——任何副本能处理任何请求 | 稳定、有序的身份(pod-0, pod-1 …) |
| 数据同步 | 不管理 | 有序滚动确保 leader/follower 同步 |
| 常见模式 | 大多数微服务 | 很多团队偏好外部 DB 而非 StatefulSet |
架构:Master 与 Worker 节点
Worker 节点组件
- 容器运行时(Container Runtime)——真正运行容器的引擎:Docker、containerd、CRI-O 或 Windows Containers。
- Kubelet——节点代理。它读 Pod 规约(YAML),把容器调度到节点上,并把节点/Pod 健康状态报告回 master。
- Kube Proxy——在网络层实现 Service 抽象。它把 Service 请求智能转发到健康的 Pod,优先同节点副本以降低延迟。
Master 节点组件
- API Server——唯一的集群网关。所有通信(kubectl、内部组件、CI/CD 流水线)都经过 API Server,它处理认证和请求校验。
- Scheduler——监视新建的、尚未分配节点的 Pod,然后根据可用 CPU 和 RAM 选最佳 worker。
- Controller Manager——运行协调循环。当它检测到期望状态(如 3 副本)偏离实际状态(2 个健康 pod)时,触发重新调度等纠正动作。
- etcd——集群的分布式键值存储——Kubernetes 的"大脑"。所有集群状态(节点、pod、配置、secret)都活在 etcd 里。没有备份就丢失 etcd 意味着丢失整个集群状态。
配置(YAML)
每个 Kubernetes 资源都声明为 YAML。四个必填顶层键是 apiVersion、kind、metadata、spec。集群持续把实际状态向声明的 spec 协调,并自动把当前状态写回 status 字段。
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app:1.0.0
ports:
- containerPort: 8080命名空间(Namespace)
命名空间在单个物理集群内提供逻辑隔离,让团队共享基础设施的同时按功能、团队或环境分隔资源。Kubernetes 自带四个内置命名空间:
- default——不指定命名空间时用户资源落到这里。
- kube-system——系统进程(API server、scheduler、etcd)。
- kube-public——可公开读取的数据,无需认证即可访问。
- kube-node-lease——用于可用性跟踪的节点心跳对象。
重要的作用域规则:ConfigMap 和 Secret 是命名空间级——每个命名空间需要自己的副本。Service 可用 FQDN service.namespace.svc.cluster.local 跨命名空间引用。Volume 和 Node 是不绑定任何命名空间的全局资源。
Helm
Helm 是 Kubernetes 的包管理器。它把一个应用的所有 YAML 清单打包成一个可分发单元,叫 Chart。Helm 还充当模板引擎——你在 values.yaml 里参数化各种值(镜像 tag、副本数、资源限制),让同一个 chart 用不同设置部署到 dev、staging、production 变得直截了当。
# 从公共仓库安装一个 chart
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install my-redis bitnami/redis \
--set auth.password=secret \
--set replica.replicaCount=2
# 列出运行中的 release
helm list
# 回滚到上一个 release
helm rollback my-redis 1工作负载控制器:DaemonSet 与 Job
DaemonSet
DaemonSet 确保在每个节点(或每个匹配选择器的节点)上恰好运行一个 Pod 副本。它是必须节点本地化的基础设施级代理的合适工具:日志采集器(Fluentd、Fluent Bit)、指标导出器(node-exporter)、网络插件(CNI 代理)、安全扫描器。当节点加入集群时,DaemonSet 控制器自动在每个新节点上放置一个 Pod;节点离开时,其 Pod 被垃圾回收。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: logging
spec:
selector:
matchLabels:
app: fluent-bit
template:
metadata:
labels:
app: fluent-bit
spec:
tolerations: # 容忍 master 节点的 taint 以便处处运行
- key: node-role.kubernetes.io/control-plane
effect: NoSchedule
containers:
- name: fluent-bit
image: fluent/fluent-bit:2.1
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
hostPath:
path: /var/logDeployment vs. StatefulSet vs. DaemonSet——决策矩阵
| 方面 | Deployment | StatefulSet | DaemonSet |
|---|---|---|---|
| Pod 身份 | 可互换——随机后缀 | 稳定:pod-0, pod-1, pod-2 | 每节点一个,以节点命名 |
| 存储 | 共享或无 | 每 Pod 一个 PVC,删除时保留 | 通常用 HostPath |
| 滚动顺序 | 并发(maxSurge / maxUnavailable) | 有序:pod-0 → pod-1 → … | 逐节点滚动更新 |
| 缩容 | 随机移除 Pod | 先移除最高序号 | 每节点一个 Pod,不手动扩缩 |
| 用例 | web 服务、API、worker | 数据库、Kafka、ZooKeeper、Elasticsearch | 日志代理、node exporter、CNI 插件 |
调度与节点亲和性
Kubernetes Scheduler 做的不止"找一个 CPU 和 RAM 够用的节点"。它应用一个精巧的两阶段算法:过滤(filtering)淘汰无法满足 Pod 需求的节点,打分(scoring)按偏好对剩余节点排序。理解这点让你能精确控制负载落在哪里。
Node Selector 与 Node Affinity
nodeSelector 是最简单形式:一组必须匹配节点标签的键值对。Node Affinity 更强大——它支持 requiredDuringSchedulingIgnoredDuringExecution(硬约束)和 preferredDuringSchedulingIgnoredDuringExecution(带权重的软偏好)。
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬约束:只用 GPU 节点
nodeSelectorTerms:
- matchExpressions:
- key: accelerator
operator: In
values: [nvidia-a100]
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution: # 软偏好:把副本分散到各 zone
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: my-app
topologyKey: topology.kubernetes.io/zoneTaint 与 Toleration
Taint 作用方向相反:它们排斥 Pod 远离节点,除非 Pod 明确容忍该 taint。常见用途包括把节点专用于特定负载(只接受 ML 作业的 GPU 节点)、把 Pod 排除在控制平面节点之外,或为维护优雅地排空节点(kubectl drain 自动加一个 NoSchedule taint)。
# 给节点打 taint,只有容忍它的 GPU Pod 才能落上去
kubectl taint nodes gpu-node-1 accelerator=gpu:NoSchedule
# Pod 必须声明这个 toleration 才能被调度到 gpu-node-1
# tolerations:
# - key: "accelerator"
# operator: "Equal"
# value: "gpu"
# effect: "NoSchedule"网络:深入 CNI、Service 与 Ingress
Kubernetes 网络遵循四条基本规则:每个 Pod 获得唯一 IP;每个 Pod 能与其他所有 Pod 无 NAT 通信;每个节点能与每个 Pod 通信;Pod 看到的 IP 与外部代理用来寻址它的 IP 一致。强制执行这些规则是容器网络接口(CNI)插件的工作。
CNI 插件
容器网络接口(CNI)是 Kubernetes 在创建或删除 Pod 时调用来配置网络接口的一套规范。流行实现的网络模型差异显著:
- Flannel——最简单;用扁平 overlay 网络(VXLAN 或 host-gw)。不支持网络策略。适合开发集群。
- Calico——基于 BGP 路由(L3 模式无 overlay)以获高性能;完整支持 NetworkPolicy,可选节点间 WireGuard 加密。
- Cilium——基于 eBPF;完全绕过 iptables,支持高吞吐服务路由和深入应用层的网络策略(L7 策略、Kafka 感知、HTTP 感知)。大规模生产集群的首选。
- Weave Net——mesh overlay;支持网络加密,但 CPU 开销比 Calico 或 Cilium 高。
Service 类型
| 类型 | 行为 | 用例 |
|---|---|---|
| ClusterIP | 仅集群内可达的虚拟 IP;默认类型 | 内部微服务间通信 |
| NodePort | 在每个节点外部 IP 的一个端口(30000–32767)上暴露 Service | 开发/测试的外部访问;不用于生产 |
| LoadBalancer | 开通一个云负载均衡器(AWS ELB、GCP LB),用外部 IP 指向 Service | 在云环境把单个 Service 暴露到公网 |
| ExternalName | 返回指向外部主机名的 CNAME DNS 别名;不做代理 | 把集群服务指向外部 DB 或 SaaS API |
| Headless (ClusterIP: None) | 无虚拟 IP;DNS 直接返回 Pod IP | StatefulSet、应用自身做服务发现(Kafka、Cassandra) |
Ingress 与 Ingress Controller
一个 Ingress 资源定义路由规则(主机名、路径前缀 → Service),但没有 Ingress Controller(一个监视 Ingress 对象并据此重配自己的运行中 Pod)它什么也做不了。常见控制器有 Nginx Ingress Controller、Traefik、HAProxy 和云原生的 AWS ALB Ingress Controller。你可以在一个集群里跑多个控制器,用 ingressClassName 注解 Ingress 来区分。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: api-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
cert-manager.io/cluster-issuer: letsencrypt-prod # 通过 cert-manager 自动签发 TLS
spec:
ingressClassName: nginx
tls:
- hosts: [api.example.com]
secretName: api-tls-cert
rules:
- host: api.example.com
http:
paths:
- path: /v1/orders
pathType: Prefix
backend:
service:
name: order-service
port:
number: 8080
- path: /v1/products
pathType: Prefix
backend:
service:
name: product-service
port:
number: 8080存储:PV、PVC 与 StorageClass
Kubernetes 通过三层层级抽象存储:PersistentVolume (PV) 表示集群中实际的存储容量(由管理员预置,或由 StorageClass 动态预置);PersistentVolumeClaim (PVC) 是用户对存储的请求,带特定大小和访问模式要求;StorageClass 定义动态创建 PV 的 provisioner 和参数。
--- StorageClass: 定义 PV 如何被动态预置
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: ebs.csi.aws.com
parameters:
type: gp3
iops: "3000"
throughput: "125"
reclaimPolicy: Retain # 删除 PVC 时不删 EBS 卷
volumeBindingMode: WaitForFirstConsumer # 在与 Pod 同一 AZ 预置
--- PVC: 用户从 fast-ssd StorageClass 申请 50 GiB
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgres-data
spec:
accessModes: [ReadWriteOnce] # 只有一个节点能读写挂载
storageClassName: fast-ssd
resources:
requests:
storage: 50Gi访问模式
- ReadWriteOnce (RWO)——被单个节点读写挂载;数据库的标准模式。注意:同一节点上的多个 Pod 都可挂载一个 RWO 卷。
- ReadOnlyMany (ROX)——被多个节点同时只读挂载;适合共享配置或模型权重。
- ReadWriteMany (RWX)——被多个节点读写挂载;需要分布式文件系统(NFS、CephFS、AWS EFS)。罕见且比块存储慢。
- ReadWriteOncePod (RWOP)——Kubernetes 1.22+;全集群只有一个 Pod 能读写挂载该卷。对 StatefulSet 比 RWO 更强。
StatefulSet 用 volumeClaimTemplates 自动为每个 Pod 创建一个 PVC(如 postgres-data-postgres-0、postgres-data-postgres-1)。这些 PVC 在 StatefulSet 缩容或删除时不会被删除——一个刻意的安全网,免得你不小心抹掉数据库。真要删数据时显式删它们。
探针与自愈
Kubernetes 为每个容器提供三种健康探针。正确配置它们,是"自愈集群"和"故障 Pod 默默接流量直到 on-call 工程师发现"之间的区别。
Liveness Probe(存活探针)
判断容器是否活着。存活探针失败会让 kubelet 杀掉并重启容器。用它来检测死锁和不可恢复的卡死——进程在跑但实际没干活的情况。注意别把初始阈值设太低:在启动期间触发的存活探针会在 Pod 就绪前杀掉它,造成重启循环。
Readiness Probe(就绪探针)
判断容器是否准备好服务流量。就绪探针失败会把 Pod 从 Service 的端点里移除——停止把流量路由给它——但容器不会被重启。这是慢启动应用、预热期或临时过载的正确探针:Pod 保持存活但被移出轮转,直到它再次发出就绪信号。
Startup Probe(启动探针)
在容器启动期间运行,在它成功前禁用存活和就绪探针。对启动时间长的应用(如 JVM 服务、加载大数据集的数据库)至关重要。一旦启动探针成功,存活和就绪探针接管。没有它,存活探针可能杀掉一个正常启动中的容器。
containers:
- name: order-service
image: order-service:2.3.1
startupProbe: # 允许最多 60s 启动
httpGet:
path: /actuator/health
port: 8080
failureThreshold: 12 # 12 * 5s = 最多 60s 启动时间
periodSeconds: 5
livenessProbe:
httpGet:
path: /actuator/health/liveness
port: 8080
initialDelaySeconds: 0 # 启动探针已处理了延迟
periodSeconds: 10
failureThreshold: 3
readinessProbe:
httpGet:
path: /actuator/health/readiness
port: 8080
periodSeconds: 5
failureThreshold: 2自动扩缩:HPA、VPA 与 Cluster Autoscaler
Kubernetes 提供三种互补的自动扩缩机制,作用于不同粒度。理解何时用哪个——以及它们如何相互作用——是常见面试话题。
Horizontal Pod Autoscaler (HPA)
HPA 根据观测指标扩缩 Pod 副本数量。默认指标是相对于 Pod 资源请求的 CPU 利用率,但通过自定义指标 API 也支持自定义指标(请求速率、队列深度、来自 Prometheus 的外部指标)。HPA 每 15 秒轮询一次 metrics server,在 minReplicas 和 maxReplicas 边界内调整副本数。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: order-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: order-service
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60 # CPU > 请求的 60% 时扩容
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: "1000" # 每副本 1000 RPS
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 缩容前等 5 分钟Vertical Pod Autoscaler (VPA)
VPA 调整单个 Pod 的 资源请求和限制(CPU 和内存),而非副本数。在 Auto 模式它会驱逐并以更新后的请求重启 Pod;在 Off 模式它只给建议。VPA 在你事先不知道合适的资源请求时有用,但它在 CPU/内存上与 HPA 冲突——用 VPA 调请求、HPA 调自定义指标,或让 VPA 只在建议模式下与 HPA 并存。
Cluster Autoscaler
HPA 和 VPA 都假设有可用节点来调度 Pod。当没有时,Cluster Autoscaler (CA) 调用云厂商 API(AWS、GCP、Azure)从集群节点组增删节点。当 Pod 因资源不足无法调度时 CA 加节点,并在可配置的冷却期(默认 10 分钟)后移除利用率低的节点。重要的是,CA 在缩容时尊重 Pod Disruption Budget:若移除某节点会违反你的 PDB,它就不会移除。
标准生产配置:HPA 基于 CPU + 自定义指标调副本数;VPA 在建议模式帮你 right-size 资源请求;Cluster Autoscaler 按需增删节点。给每个容器设置资源 requests 和 limits——没有 requests,HPA 就没有计算利用率的基线,scheduler 也无法做出明智的放置决策。
Operator 模式
Kubernetes Operator 是一个自定义控制器,把某个特定应用的运维知识编码进代码。它用 自定义资源定义(CRD) 扩展 Kubernetes API——加入像 PostgresCluster、KafkaCluster 或 ElasticsearchCluster 这样的新资源类型——并运行一个控制循环,监视这些资源并把集群驱向它们声明的期望状态。
为什么有 Operator
Kubernetes 原生地把无状态负载处理得很漂亮:部署、扩缩、回滚。但有状态系统——数据库、消息代理、搜索引擎——需要领域特定的运维逻辑:初始化集群、选举 leader、执行尊重 quorum 的滚动升级、做一致备份、从快照恢复。人类运维通过执行 runbook 编码这些知识;Kubernetes Operator 把它自动化。
# 用 CloudNativePG Operator 声明一个 PostgreSQL 集群
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: orders-db
spec:
instances: 3 # 1 主 + 2 副本
primaryUpdateStrategy: unsupervised
storage:
size: 100Gi
storageClass: fast-ssd
backup:
barmanObjectStore:
destinationPath: s3://my-bucket/backups/orders-db
s3Credentials:
accessKeyId:
name: s3-creds
key: ACCESS_KEY_IDCloudNativePG Operator 看到这个 Cluster CR 后处理其余一切:创建主 Pod、给副本设置流式复制、为每个 Pod 配置 headless Service 实现稳定 DNS 名、为主写 vs 副本读配置独立 Service、设置到 S3 的持续 WAL 归档,以及执行在关停主之前先提升副本的滚动升级以最小化停机。所有这些运维复杂度——本需一份冗长 runbook——如今都编码为代码,由一份 YAML 声明触发。
流行的 Operator
- Strimzi——把 Kafka 集群和主题作为 CRD;管理 broker、ZooKeeper、Kafka Connect 和 MirrorMaker 2。
- Prometheus Operator——
ServiceMonitor、PodMonitor和PrometheusRuleCRD,声明式地配置抓取目标和告警规则。 - cert-manager——
Certificate和ClusterIssuerCRD,从 Let's Encrypt 或私有 CA 自动签发和续期 TLS 证书。 - Argo CD——GitOps operator,把集群状态协调成与 Git 仓库一致,让每次部署都是一次 git commit。
- KEDA(Kubernetes 事件驱动自动扩缩)——基于外部事件源扩缩 Deployment 和 Job:Kafka 消费者 lag、SQS 队列深度、HTTP 请求率——弥合 HPA 以 CPU 为中心的模型与事件驱动负载之间的鸿沟。
资源管理:Requests、Limits 与 QoS 类别
每个容器都应声明 CPU 和内存的 requests(scheduler 使用的保证分配)和 limits(容器可消耗的上限)。两者关系决定 Pod 的 QoS 类别,它控制节点内存压力下的驱逐优先级。
| QoS 类别 | 条件 | 驱逐优先级 |
|---|---|---|
| Guaranteed | Pod 里每个容器 requests == limits | 最后被驱逐;预留容量 |
| Burstable | 至少一个容器设了 requests,但 requests < limits | 在 BestEffort 之后驱逐;按相对 request 的内存用量排序 |
| BestEffort | 完全没设 requests 或 limits | 内存压力下最先被驱逐 |
把 CPU requests 设为你的稳态用量、CPU limits 设为 requests 的 2–4 倍以允许突发。对内存,把 requests 设为你的 p99 用量、对延迟敏感的服务把 limits = requests(即 Guaranteed 类)——超过内存 limit 的容器会被立即 OOMKilled;超过 CPU limit 的 pod 只会被限流(不被杀),所以内存 limit 后果严重得多。
把 Kubernetes 想成一个自愈的、声明式的控制循环:你用 YAML 描述你想要什么,master 节点的 Controller Manager 持续把实际状态向它驱动。Pod 给你隔离;Service 给你稳定寻址;etcd 给你持久的集群记忆;Helm 给你可复用、有版本的打包。叠加 HPA + Cluster Autoscaler 实现弹性,用 Operator 处理有状态应用,用恰当的探针配置让自愈循环真正生效。
Pod 崩溃时会发生什么?Controller Manager 检测到偏离期望副本数,指示 Scheduler 放置一个新 Pod——整个过程 Service 的 IP 保持不变。
Deployment vs StatefulSet vs DaemonSet?Deployment 给无状态应用(可互换 Pod);StatefulSet 给数据库(稳定有序 Pod 身份、每 Pod 一个 PVC);DaemonSet 给节点本地基础设施代理(每节点一个 Pod)。
etcd 为什么关键?它是所有集群状态的唯一真相来源;没有备份就丢失 etcd 意味着丢失整个集群配置。
HPA vs VPA vs Cluster Autoscaler?HPA 扩缩副本数;VPA 调每 Pod 资源请求;Cluster Autoscaler 增删节点。三者一起用:HPA 用自定义指标、VPA 用建议模式、CA 来供给容量。
liveness vs readiness probe?liveness 失败杀掉并重启容器;readiness 失败把它移出 Service 端点而不重启——预热和临时过载用 readiness。
Operator 模式是什么?一个把运维 runbook 编码为代码的自定义控制器,用 CRD 把 Kubernetes API 扩展出领域特定资源类型,如 KafkaCluster 或 PostgresCluster。