数据模型是任何系统里最有后果的决策。它们塑造的不只是软件如何被写,还有我们如何思考问题本身。第 2 章纵览三个主流家族——关系、文档、图——并考察各自天然搭配的查询语言。
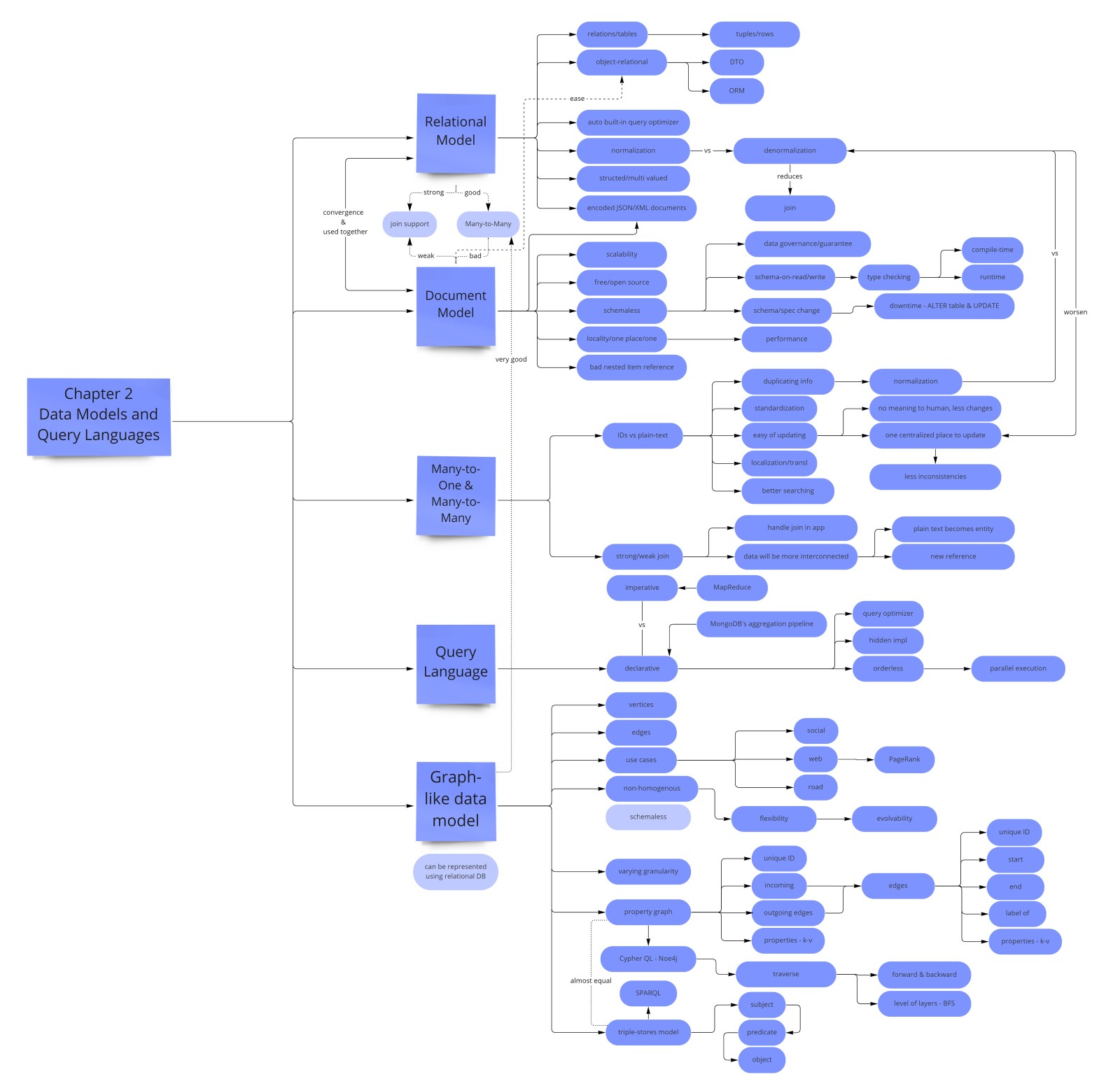
- 关系模型(1970,Codd)——数据是元组的表;SQL 是声明式的;查询优化器选访问路径。最适合多对多 join 和强制 schema。
- 阻抗失配(impedance mismatch)——代码里的对象 vs 表里的行需要一个 ORM 翻译层,它能隐藏 N+1 查询这类性能问题。
- 文档模型——存自包含的 JSON/BSON blob;一对多极好(嵌入子项);多对多差(需应用级 join)。
- 读时 schema ≠ 无 schema——schema 隐式存在于应用代码里;像动态类型检查 vs 静态类型检查。
- 图模型——顶点 + 带标签有向边 + 属性 map;对哪些顶点能连接无 schema 限制。当关系即数据时最适合。
- 声明式胜出——SQL/Cypher 让优化器决定执行计划,无需改查询就能透明地提升性能。
关系模型在多对多 join 和强 schema 保证上胜出。文档模型在自包含层级数据和 schema 灵活性上胜出。图模型在关系即数据时胜出。了解取舍;大多数生产系统三者混用。
原始笔记
本章总结所基于的手写学习笔记:
关系模型 vs 文档模型
Edgar Codd 在 1970 年提出关系模型:数据组织成关系(relation,表),每个是元组(tuple,行)的集合。关系模型的关键洞见是应用代码不需要知道物理存储布局——数据库引擎处理它,暴露一个干净的声明式查询接口。数十年里它主导每个严肃的数据系统,SQL 至今仍是数据工程的通用语。
NoSQL 在 2010 年代显著兴起,由几个不同动机驱动:需要比单个 SQL 数据库能提供的更大写可扩展性;快速演进的初创公司里快速变化数据模型的 schema 灵活性;某些在表里难表达的数据结构的更好阻抗匹配;以及对地理分布、高可用系统的渴望,那里严格关系一致性是瓶颈。"NoSQL"是覆盖文档存储、键值存储、宽列存储和图数据库的宽泛伞——它们只共享不用关系模型这一属性,彼此的取舍差异巨大。
简历例子:为什么文档感觉自然
Kleppmann 用一个 LinkedIn 风格的简历(用户资料)作贯穿例子,值得细拆,因为它干净地说明每个模型何时胜出。简历有层级结构:一个用户身份,但可能有许多职位(各带公司、头衔、起止日期)、许多教育条目、许多技能、许多联系方式。这是一个从单根实体辐射出的经典一对多结构。
关系数据库里你把它建模为独立表:users、positions、education、skills。每个子表有指回用户的外键。读一份完整资料需要跨所有这些表 JOIN——或多次顺序查询。写一份新资料需要往多个表插行,理想在一个事务里。数据是规范化的:用户名恰好出现在一处。
文档数据库(MongoDB、CouchDB、DynamoDB 文档模式)里你把整份资料存成一个 JSON 文档。职位是直接嵌在用户文档里的子对象数组。读一份完整资料是一次文档取——无需 JOIN。数据局部性自然。整份资料自包含。
对这个特定用例——读一份完整资料、写一份完整资料——文档模型在简单性和读性能上胜出。当主导访问模式是"取这个用户的完整资料"时,关系模型的规范化好处(消除冗余、支持跨所有资料的灵活查询)就不那么要紧。
对象-关系阻抗失配
今天大多数应用代码用面向对象或函数式语言写。应用代码里数据的自然单位是带嵌套字段的对象或 struct。关系数据库里数据的自然单位是扁平表里的一行。这两种表示间的翻译——通常由 Hibernate(Java)、ActiveRecord(Ruby)、SQLAlchemy(Python)或 Prisma(TypeScript)等 ORM 框架处理——就是阻抗失配。
阻抗失配不只是个不便。它引入几类真实问题:
- N+1 查询问题:ORM 取 N 条父记录,然后懒执行 N 个独立查询取每个父的子项——总共 N+1 次数据库往返,而一个 JOIN 本可一次搞定。ORM 能用 eager loading 缓解,但开发者必须知道去配置它,且在代码评审里容易漏掉。
- 双重心智模型:开发者必须同时维护代码里对象图的心智模型和数据库里关系 schema 的心智模型。随着一方被更新而另一方没有,它们随时间不可避免地微妙分歧。
- Schema 迁移耦合:给应用对象加一个字段需要数据库 schema 迁移(ALTER TABLE),它可能锁表、需要部署协调,并破坏滚动部署期间仍在运行的旧应用实例的向后兼容。
- ORM 生成的查询质量:ORM 能生成出人意料低效的 SQL——笛卡尔积、冗余子查询或缺失索引——对开发者不可见,直到某个查询在生产中变慢。
N+1 查询问题是生产系统里最常见的 ORM 相关性能问题。若你有一个订单列表、想显示每个订单的客户名,朴素的 ORM 取 100 个订单可能发 101 个数据库查询(1 个查订单 + 100 个查客户)而非 1 个带 JOIN 的查询。开发中总检查 ORM 生成的 SQL,并为已知访问模式显式配置 eager loading。
一对多、多对一、多对多
你数据的关系结构是选哪个数据模型的最可靠向导。Kleppmann 把关系分成三类,各自取舍不同。
一对多关系(一个用户有许多职位;一篇博文有许多评论;一个订单有许多行项)是文档模型的强项。"多"那侧能作为数组嵌在父文档里。读对局部性友好;整个层级在一处。文档数据库在这里发光。关系模型能通过带外键的子表处理这个,但它需要文档模型避开的 JOIN。
多对一关系(许多用户住在同一城市;许多商品属于同一分类;许多员工在同一公司)在关系数据库里倾向规范化。你把城市存为 cities 表里的一行,按 ID 引用。这消除冗余:若城市名改了,你更新一行,而非数千条用户记录。它也支持引用完整性:你无法插入一个 city_id 不存在的用户。
文档数据库对强制多对一引用完整性支持弱或无。Join 要么是应用级(取用户,再在第二个查询里按 ID 取城市)要么完全不支持。这是文档模型的核心弱点:它把"嵌入子项"情况处理得好,但把"引用共享数据"处理得差。实践中这意味着文档数据库鼓励反规范化——把城市名直接存进用户文档——这造成更新异常:若城市名改了,你必须找到并更新每个含它的用户文档。
多对多关系(一本书有许多作者;一个作者有许多书;一个标签应用于许多帖子;一个帖子有许多标签)是文档模型最挣扎的地方。你不能简单嵌入:你不能在每个标签文档里嵌入作者的所有书、又在每个作者文档里嵌入所有标签,而不造成大量冗余。关系模型用一个 join 表(带 book_id 和 author_id 的 book_authors)干净处理这个。图数据库对高度连接的多对多数据更自然。
这段历史弧值得理解。1960、70 年代早期的网络模型数据库(IMS、CODASYL)把数据建模为带记录间链接的记录树。多对多关系通过跟随指针手动导航——CODASYL 称之为"访问路径"。一个查询本质是一个程序:遍历这个链接,再那个链接,然后找匹配记录。这强大但要求开发者知道数据的物理布局并显式写导航代码。加一个新访问路径常需要重写查询。关系模型的革命性贡献是消除手动路径导航——查询优化器选访问路径,解放开发者只想他们要什么数据,而非如何取它。
规范化:为什么重要
规范化是构造关系数据库以减少数据冗余、改善数据完整性的过程。关键想法:每个事实恰好出现在一处。若城市名存在 cities 表里、别处都按 ID 引用,改城市名需要一次更新。若城市名冗余地存在每条用户记录里,改名需要跨可能数百万行的批量更新——且若任何行漏了更新,数据就变得不一致。
规范化用冗余换 join 复杂度。规范化数据库更小、更一致、更易正确更新;但读数据的反规范化视图需要 join,它比简单查找更昂贵。这是关系模型通过其查询优化器和索引机制管理的根本张力。文档数据库倾向反规范化(嵌入数据、避开 join),接受冗余以换取更快的读和对主导访问模式更简单的查询。
实践中,"完全规范化"和"完全反规范化"是一个谱系的两端。生产系统常在中间某处——对频繁更新的参考数据高度规范化,对频繁读、很少更新的聚合选择性反规范化。物化视图、读副本和缓存层的兴起可看作受管理的反规范化——保持规范化数据为真相来源,同时服务反规范化视图以获读性能。
读时 Schema vs 写时 Schema
| 属性 | 写时 Schema(关系) | 读时 Schema(文档) |
|---|---|---|
| Schema 强制 | 写时由 DB;无效数据被拒 | 读时由应用代码;DB 接受任何东西 |
| 加新字段 | ALTER TABLE 迁移(可能锁表、需协调) | 直接开始写新文档;旧的返回 null/缺失字段 |
| 异构数据 | 难——每行必须符合 schema | 易——同集合不同文档可有不同字段 |
| 数据完整性 | 由 DB 约束保证(NOT NULL、FOREIGN KEY、CHECK) | 应用的责任——坏数据能被写入,只在读时失败 |
| 查询灵活性 | 强——优化器处理多表 join 和任意过滤 | 弱——多文档 join 支持差;跨集合查询需应用逻辑 |
| Schema 演化 | 显式、有版本、可原子——但迁移是运维风险 | 隐式、渐进、默认向后兼容——但无强制 |
读时 schema 有时被称"无 schema",但 Kleppmann 正确指出这有误导——schema 不是缺席,只是隐式在应用代码里。每行从文档读字段的代码都嵌入了哪些字段存在、它们是什么类型的假设。若那个假设被违反(因为旧文档结构与新的不同),应用在运行时而非写时崩溃。Kleppmann 用的类比很精确:写时 schema 像静态(编译期)类型检查——错误被早抓,在数据到达存储前。读时 schema 像动态(运行时)类型检查——错误只在有问题的数据被访问时浮现。
两种方法都非普遍优越。写时 schema 在数据完整性至上、schema 稳定、查询跨许多异构记录时更好。读时 schema 在每项结构真正可变(日志里不同类型的事件、有不同属性集的商品)、schema 演化需要不带协调迁移地快速发生,或数据来自你无法控制的外部系统时更好。
数据局部性及何时要紧
文档数据库常把一个文档存为单个连续编码 blob(MongoDB 里 JSON、Couchbase 里 BSON、DynamoDB 里二进制编码)。若你的应用频繁需要整个文档——整份用户资料、带所有行项的整个订单——这种数据局部性是真正的性能优势:单次磁盘读取回你需要的一切,而非跨用外键 join 的表多次读。
局部性优势在几种情况消失——甚至反转。若你通常只需要文档字段的一小子集,你仍加载整个 blob,浪费 I/O。若文档变得很大(嵌入数组有数百条),随机访问中间变昂贵。若文档被以增大其尺寸的方式更新,许多文档数据库必须把整个文档重写到磁盘新位置,使更新比原地行更新更昂贵。因此局部性对作为整体读取、作为整体很少写、尺寸相对有界的文档帮助最大。
Kleppmann 也注意关系数据库有自己的局部性机制。Google 的 Spanner 允许声明一张表 interleaved 在另一张内(磁盘上物理共置)。Oracle 的多表 cluster 把不同表的相关行存在同一磁盘块。Cassandra 和 HBase 等列族数据库允许把频繁一起访问的列分组进同一存储单元。局部性是一个谱系,而非文档 vs 关系系统的二元特性。
查询语言:声明式 vs 命令式
一个模型搭配的查询语言与模型本身一样重要,因为它决定什么能被高效表达、引擎有什么优化机会。Kleppmann 在声明式和命令式方法间划出鲜明区别。
声明式查询语言:SQL
SQL 是声明式的:你描述你要什么数据,而非数据库应采取什么步骤去取它。SELECT * FROM users WHERE city_id = 42 ORDER BY last_name 对是否用索引、应用哪种 join 算法、是否并行执行只字未提。那些决策属于查询优化器。什么(查询)与如何(执行计划)之间的这种分离在架构上意义深远。
因为查询是规约而非程序,数据库引擎能自由重写它。优化器能基于表统计在顺序扫描和索引扫描间选。它能重排 join、下推过滤、应用人类开发者绝不会手动写的转换。当 PostgreSQL 在新版本改进其查询优化器,所有现有查询自动受益——无需应用代码变更。这种透明性是声明式查询语言最被低估的属性之一。
CSS 选择器和 XPath 也是声明式的,Kleppmann 用它们作说明性类比。当你写 li.selected > p { color: green; },你在指定关于哪些元素要样式化的规则,而非遍历算法。浏览器的 CSS 引擎处理匹配。若引擎被优化,你的样式渲染更快而你的 CSS 毫无改变。
MapReduce:介于声明式和命令式之间
MapReduce 是一个编程模型(不是查询语言),用于跨许多机器并行处理大数据集,由 Google 2004 年论文推广、在 Hadoop 里实现。开发者写两个函数:一个把每条输入记录转成键值对的 map 函数,和一个聚合每个 key 所有值的 reduce 函数。框架处理并行化、shuffle 和容错。
MapReduce 既非纯声明式也非纯命令式。map 和 reduce 函数用通用语言(Java、Python、Go)写,这给完整表达力——你能表达任何你能写代码的转换。代价是框架无法在你显式编码之外优化执行。没有查询优化器为效率重写你的 map 函数。MongoDB 最初用基于 JavaScript 的 MapReduce 做复杂聚合;它后来加了聚合管道(一个更声明式、可组合的阶段序列),引擎能更好地优化,大多数开发者觉得更易用。
-- 声明式 SQL:优化器选执行计划
SELECT region, COUNT(*) AS cnt
FROM observations
WHERE animal_family = 'Sharks'
AND date_part('year', observation_date) = 2023
GROUP BY region;
-- MapReduce 等价(伪代码):开发者控制执行
map(record):
if record.family == 'Sharks' and record.year == 2023:
emit(record.region, 1)
reduce(region, counts):
emit(region, sum(counts))SQL 版更短、更可读,且受益于优化器应用统计知识的能力。MapReduce 版更灵活——你能在 map 函数里加任意复杂逻辑——但让它正确高效是开发者的活。对大多数分析聚合,SQL 方法更优。MapReduce 的价值在 SQL 能力系统还无法在 Hadoop 集群规模运作的时代;今天大多数大规模分析用 SQL-on-Hadoop 引擎(Hive、Presto、Spark SQL),把 SQL 编译成分布式执行计划。
图数据模型
当多对多关系不只是存在而是无处不在——当实体间的关系与实体本身一样有趣——关系模型和文档模型都不特别自然。关系数据库能建模图(顶点作一张表里的行、边作另一张表里的行),但图遍历查询(找两节点间所有路径、数共同好友、识别社区)变成笨重的递归 SQL。文档数据库建模图更别扭。图数据库(Neo4j、Amazon Neptune、JanusGraph、TigerGraph)提供专为这种访问模式设计的模型和查询语言。
属性图(Property Graph)
属性图模型——Neo4j 和大多数流行图数据库使用——由以下组成:
- 顶点(也叫节点):人、地点、事件等实体。每个顶点有唯一 ID、一组标签(如 "Person"、"Location"),和一个属性 map(键值对)。
- 边(也叫关系):顶点间的有向连接。每条边有唯一 ID、一个标签(如 BORN_IN、LIVES_IN、MARRIED_TO)、一个尾顶点(起点)、一个头顶点(终点),和自己的属性 map。
关键地,对哪些顶点能连接到哪些顶点无 schema 限制。一条 BORN_IN 边能连接一个 Person 顶点到一个 City 顶点、或一个 Country 顶点、或任何其他顶点。这种灵活性使扩展数据模型变容易:加一个新关系类型不需要任何 schema 变更。数据模型随新关系类型被发现而有机生长。
两个重要实现注解:任何顶点都能高效地通过其出边和入边找到(图在两个方向可导航)。顶点和边都能携带任意键值属性,所以你能给关系本身附元数据(如一条 MARRIED_TO 边可有一个表示结婚年份的 since 属性)。
Cypher 查询语言
Cypher 是 Neo4j 的声明式图查询语言。它用一种视觉化的 ASCII-art 模式语法描述图结构,使它即便对中等复杂查询也极可读。模式 (person)-[:BORN_IN]->(city)-[:WITHIN*0..]->(country {name: 'United States'}) 应读为:"找一个通过 BORN_IN 边连到 city 顶点、又通过任意数量 WITHIN 边连到名为 United States 的 country 顶点的 person 顶点。"*0.. 意思是"遍历零或多条 WITHIN 边"——一个沿位置层级(城市 → 州 → 国家)递归的变长路径。
-- 找在美国出生、现住欧洲的人
MATCH
(person)-[:BORN_IN]->()-[:WITHIN*0..]->(usa:Location {name:'United States'}),
(person)-[:LIVES_IN]->()-[:WITHIN*0..]->(eu:Location {name:'Europe'})
RETURN person.name
-- 等价 SQL 需要递归 CTE,冗长得多
WITH RECURSIVE within_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'United States'
UNION
SELECT e.tail_vertex FROM edges e, within_usa w
WHERE e.head_vertex = w.vertex_id AND e.label = 'within'
)
-- ... 然后为 born_in 和 lives_in 再做 joinCypher 版不只更短——它结构上比 SQL 版更接近你如何思考这个问题("找在美国出生、住欧洲的人"),SQL 版需要显式递归和手动 join 构造。对涉及变长路径和图遍历的查询,Cypher(及类似图查询语言)在不用 WITH RECURSIVE 的情况下确实比 SQL 更具表达力。
三元组存储与 SPARQL
三元组存储把所有数据建模为(主语,谓语,宾语)三元组。例如:(Jim, likes, bananas)、(Jim, bornIn, Berlin)、(Berlin, type, City)。当宾语是另一个资源(而非字面字符串或数字),三元组编码图里的一条边:(Jim, bornIn, Berlin) 是从 Jim 顶点到 Berlin 顶点、标签为 "bornIn" 的边。这意味着每个属性图都能表达为一组三元组——两模型在表达力上等价,它们在语法和生态上不同。
RDF(资源描述框架),由 W3C 开发,是最广用的三元组存储格式。主语和谓语是 URI(全局唯一标识符),使 RDF 数据可跨源组合——你能合并来自不同组织的 RDF 数据集而无重命名冲突。SPARQL(SPARQL 协议与 RDF 查询语言)是 RDF 三元组存储的声明式查询语言。它有一个精神上类似 Cypher 的模式匹配语法。
Datalog 是 SPARQL 更早的前身,基于 Prolog 的逻辑编程方法。它定义规则:若这些事实成立,则推出这个派生事实。Datalog 是 Datomic(Rich Hickey 的不可变数据库)的基础,并出现在演绎数据库的学术研究里。它比 SPARQL 更通用——你能表达递归和复杂派生事实——但对不熟悉逻辑编程的开发者也更难读。Kleppmann 收入它以展示声明式查询模型的完整广度。
| 模型 | 最适合 | 查询语言 | 示例系统 |
|---|---|---|---|
| 关系 | 结构化表格数据;带 join 的多对多;强制 schema;金融/事务数据 | SQL | PostgreSQL、MySQL、Oracle、SQL Server |
| 文档 | 自包含层级记录;schema 灵活;一对多嵌入关系;异构项类型 | MongoDB 查询 API、DynamoDB 表达式 | MongoDB、CouchDB、DynamoDB、Firestore |
| 属性图 | 高度连接数据;变长路径查询;社交网络、知识图谱、推荐引擎 | Cypher、Gremlin | Neo4j、Amazon Neptune、JanusGraph |
| 三元组存储 | 语义数据;全局联邦数据集;知识工程;本体 | SPARQL、Datalog | Datomic、Apache Jena、Amazon Neptune (RDF) |
为什么数据模型比你想的更重要
Kleppmann 用一个值得停顿的观察开篇:"数据模型也许是开发软件最重要的部分,因为它们有如此深远的影响:不只在软件如何被写,还在我们如何思考我们正在解决的问题。"这不是夸张。一个数据模型塑造的不只是数据库 schema 而是整个系统的词汇——什么概念存在、它们如何关联、什么操作自然、什么别扭。
给社交网络图选关系模型意味着"找我的二度连接"变成一个递归 SQL 查询——可能但不自然。选图模型意味着它变成一行 Cypher 模式——查询结构镜像问题结构。数据模型决定什么容易、什么难,而那塑造什么功能被构建、什么被推迟为"太复杂"。只懂一种数据模型的工程师会试图把每个问题塞进它,常产出比所需更难构建、更难理解、更难扩展的系统。
没有单一数据模型普遍胜出。选择应由你数据的关系结构和主导访问模式驱动。带一对多子项的自包含层级记录 → 文档模型。带复杂多对多 join 和 schema 强制的结构化数据 → 关系。关系是一等公民、路径查询常见的高度连接数据 → 图。面试中拿不准时:从关系开始(它最熟悉、最通用),然后通过指出数据的某个具体结构属性来证明任何偏离——而非只说"NoSQL 更能扩展"(如此表述几乎总是错的)。
什么时候选文档 DB 而非关系 DB?当数据真正是自包含层级记录(带嵌入职位的用户资料、带嵌入变体的商品)、你很少需要跨文档 join,且 schema 字段演化频繁到 ALTER TABLE 迁移运维上痛苦时。别只为"扩展"选文档——关系数据库用读副本和分区扩展得很好。
什么是阻抗失配?内存对象(应用代码里的类/struct)与扁平关系行/表之间的翻译鸿沟,由 ORM 桥接。N+1 查询问题是最常见的性能后果:取 N 个父触发 N 个独立子查询而非一个 JOIN。
读时 schema vs 写时 schema——哪个更好?都非普遍。写时 schema(关系)早抓数据质量问题并让数据库保证完整性。读时 schema(文档)允许异构文档和更快 schema 演化。类比是静态 vs 动态类型检查——不同语境不同取舍。
SQL 为什么是声明式、为什么重要?你描述你要什么数据;查询优化器决定如何取——哪个索引、哪种 join 算法、是否并行。这意味着改进优化器的数据库版本升级透明地改进所有查询,而无任何应用代码变更。
什么时候用图数据库?当关系遍历是主导查询模式、关系深度可变或无界时——社交网络好友的好友查询、推荐引擎、欺诈检测(识别连接账号)、知识图谱。关系能建模图但递归 SQL 冗长且常慢;图数据库使遍历查询自然且快。