像 Google Maps 这样的地图平台跨极其不同的用例服务数十亿用户——逐向导航、商家发现、卫星影像、交通感知路由,以及 Uber 等应用的第三方集成。在 30 亿月活和 1000 万 API 伙伴下,它是现存最数据密集、最延迟敏感的系统之一。核心挑战不是存储世界路网——而是为数百万并发用户在数十毫秒内回答"此刻两点间最快路线是什么?",同时持续从数十亿位置 ping 集成新鲜交通数据。
- Geohash 把 2D 编码为 1D——把 lat/lng 转成可排序字符串,在标准键值存储(BigTable/DynamoDB/Cassandra)上支持高效范围查询。
- 预计算路线——Dijkstra 是 O((V+E)logV);3B 用户下太慢。存 section 节点间预计算路线;只有最后的微段实时计算。
- Contraction Hierarchies——离线节点重要性排名让查询时双向 Dijkstra 跳过低重要性节点,相比朴素 Dijkstra 提速 1000×。
- 导航用 WebSocket——双向持久连接;一个 WebSocket Manager 把用户 ID 映射到 server:port 做路由。
- 位置 ping 至多一次——GPS 每 5s 发;丢一个包可接受,保证投递的开销不可。
- CDC → Elasticsearch——地图变更流经 Kafka 使搜索索引最终一致。
- 地图瓦片从 CDN 服务——按 zoom/x/y 为键的预渲染栅格瓦片;系统里最可缓存的对象。
预计算 section 节点间路线并存在 geohash 索引的键值存储(BigTable/DynamoDB/Cassandra)。用 Contraction Hierarchies 离线使查询时路由比朴素 Dijkstra 快 1000×。导航用 WebSocket。把用户位置 ping(每 5s,至多一次)喂进消息队列。瓦片从 CDN 服务。让 CDC 驱动的 Kafka 使 Elasticsearch 搜索索引与地图变更保持最新。把 ML 驱动的 ETA 精炼和热点预测推到离线。
第 1 步 — 澄清需求
地图平台看似宽泛。面试中把它界定成一个具体的面是一半的功劳。陈述你会覆盖什么并显式指出你不会的。
功能
- 在渲染的地图上识别道路、地点和兴趣点。
- 计算考虑交通、路况和实时事件的准确距离和 ETA。
- 逐向导航,偏离或新事件时实时重路由。
- 附近搜索:在半径内找餐厅、加油站、医院。
- 多缩放级别的地图瓦片渲染。
- 为第三方集成(打车、车辆制造商、数据提供商)提供可插拔 API。
非功能
- 低延迟——路线查询必须 <100 ms p99 返回;瓦片从 CDN 缓存 50 ms 内加载。
- 高可用——行程中导航失败是关键用户体验;目标 99.99%。
- 海量规模——30 亿月活、1000 万 API 伙伴。
- 地图数据最终一致可接受——新加的路在搜索里晚 30 秒出现没问题;错误路线不行。
- 地图编辑持久性——用户提交的更正不能丢失。
区分读路径(瓦片、路由、搜索)和写路径(地图编辑、实时交通摄取)。它们一致性要求差异很大,几乎能独立设计。早点指出这个拆分——面试官奖励它。
第 2 步 — 容量估算
Google Maps 服务大约 10 亿日活(DAU)。为三种主要流量类型——瓦片取、路线请求、位置 ping——做粗略估计。
地图瓦片流量
- 每个地图视图加载 ~10–20 个瓦片(视口周围 3×3 或 4×4 网格)。
- 1B DAU × 20 会话/天 × 15 瓦片/会话 = 3000 亿瓦片取/天 ≈ 3.5M 瓦片/秒。
- 绝大多数从 CDN 边缘缓存服务——源瓦片服务器只处理缓存未命中(<1% 请求)。
- 瓦片存储:世界跨所有缩放级别有 ~4.5 万亿瓦片;每栅格瓦片 ~20 KB,约 90 PB 瓦片数据——瓦片存储用分布式对象存储(GCS/S3)、只有热门缩放级别完全预渲染的原因。
路线请求
- 假设 10% DAU 每天请求一条路线:100M 路线请求/天 ≈ ~1,200 路线 QPS平均,5× 峰值 → ~6,000 路线 QPS。
- 每个路线请求可能扇出到 3–5 条备选路线,所以路由引擎峰值处理 ~30K 子查询/秒。
位置 Ping(活跃导航)
- 假设峰值(通勤时段)50M 用户同时导航。
- 每个导航者每 5 秒发一个 GPS ping:50M / 5 = 10M 位置写/秒。
- 每个 ping ~100 字节:10M × 100B = ~1 GB/秒入站位置数据——必须被横向分区的消息队列吸收。
地图数据存储
- 路网图:~50M 节点(交叉口)× 200B + ~100M 边 × 100B ≈ 原始图 ~20 GB(在大机器上装进内存,支持内存路由)。
- 地点/POI 数据:~500M 地点 × ~500B ≈ 地点数据库 ~250 GB。
- 交通数据:流式,保留 30 天 → 压缩存储约 ~10 TB 历史交通。
第 3 步 — API 设计
通过 API 网关暴露干净的 REST 端点。面试目的三个最重要的面是瓦片服务、路由和附近搜索。
# 地图瓦片 — zoom/x/y 遵循标准 slippy map 方案
GET /tiles/{zoom}/{x}/{y}.png
→ 200 image/png(从 CDN 边缘服务,TTL ~7d)
# 路线计算
POST /api/route
{ origin: {lat, lng}, destination: {lat, lng},
mode: "driving"|"walking"|"transit",
alternatives: true }
→ { routes: [{ polyline, distance_m, duration_s, eta }] }
# 附近搜索(半径米)
GET /api/places/nearby?lat=37.7&lng=-122.4&radius=500&type=restaurant
→ { places: [{ place_id, name, lat, lng, rating }] }
# 地理编码(地址 → 坐标)
GET /api/geocode?address=1600+Amphitheatre+Pkwy
# 反向地理编码(坐标 → 地址)
GET /api/reverse-geocode?lat=37.42&lng=-122.08
# 导航会话(WebSocket 升级)
GET /ws/navigate?route_id=abc123
→ WS 流: { type: "update", eta_s, next_maneuver, reroute? }两个值得指出的设计选择:瓦片端点用 slippy map(XYZ)方案,使瓦片 URL 确定且最大可缓存——同一瓦片 URL 能全球缓存而无任何 query-string 变化。导航端点升级到 WebSocket,使服务器能推送 ETA 更新和重路由指令而无需客户端轮询。
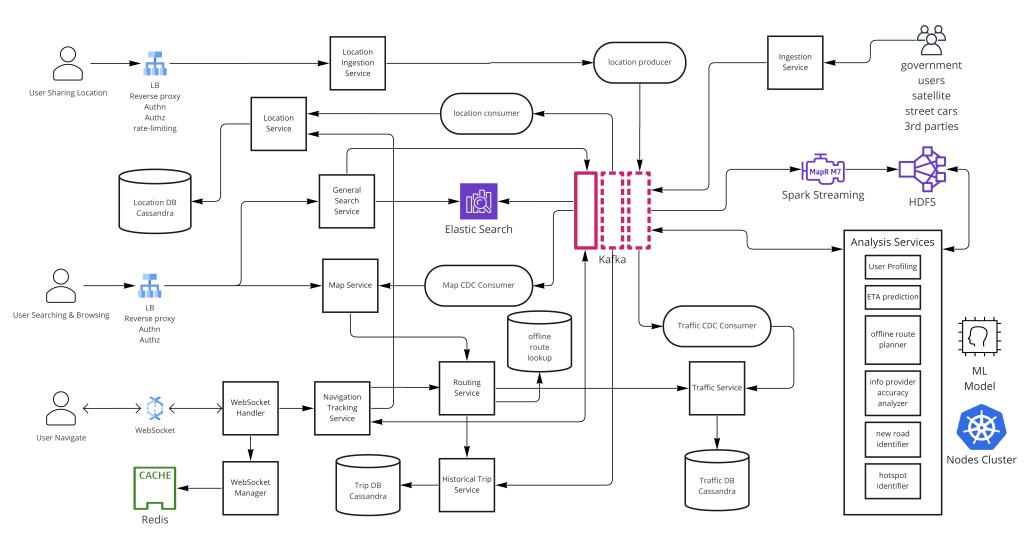
第 4 步 — 地图数据:摄取与存储
初始地图数据来自政府市政地图(如 USGS、Ordnance Survey)、卫星影像提供商(Planet、Maxar)、街景影像车辆,和第三方地理数据提供商。持续更新经用户提交反馈、商家提交和持续卫星刷新到达。OpenStreetMap 志愿者大规模贡献更正。
所有地图修改经 Kafka 通过变更数据捕获(CDC)处理,使下游消费者——搜索索引器、路线预计算器、瓦片渲染器、分析服务——能异步反应地图变更而不把摄取路径耦合到下游写延迟。
数据模型:路网图
路网建模为有向加权图。每个交叉口是一个节点;两个交叉口间的每个道路段是一条有向边,属性包括距离、限速、平均行驶时间、道路等级(高速、主干、本地)和转向限制。
CREATE TABLE nodes (
node_id BIGINT PRIMARY KEY,
lat DOUBLE NOT NULL,
lng DOUBLE NOT NULL,
geohash VARCHAR(12), -- 预计算,已索引
node_type VARCHAR(20) -- intersection | endpoint | poi
);
CREATE TABLE edges (
edge_id BIGINT PRIMARY KEY,
from_node BIGINT REFERENCES nodes(node_id),
to_node BIGINT REFERENCES nodes(node_id),
distance_m INT NOT NULL,
speed_limit SMALLINT, -- km/h
road_class SMALLINT, -- 0=高速 .. 5=本地
base_weight FLOAT, -- 静态行驶时间秒
current_weight FLOAT -- 交通调整,~5 分钟刷新
);
CREATE TABLE places (
place_id BIGINT PRIMARY KEY,
name VARCHAR(255),
lat DOUBLE,
lng DOUBLE,
geohash VARCHAR(12),
category VARCHAR(64),
rating FLOAT,
address TEXT
);第 5 步 — 空间索引:Geohash、Quadtree 与 S2
核心空间索引挑战是在数据库规模高效回答"给我这个边界框内的所有路网节点/地点"。三个互补结构驱动现代地图系统的地理空间查询:
Geohash
Geohash 把一个 2D (lat, lng) 坐标编码成一个 1D 可排序 Base32 字符串。每个额外字符大约把精度提升四倍:6 字符 geohash 覆盖 ~1.2 km × 0.6 km;9 字符哈希覆盖 ~5 m × 5 m。关键洞见是附近位置共享一个公共前缀——所以 geohash 列上的范围扫描取出空间上附近的记录而无任何特殊空间数据库扩展。这使它与任何支持高效前缀查询的键值存储(BigTable、DynamoDB、Cassandra)兼容。
-- 用 geohash 前缀的附近地点查询
FUNCTION nearby_places(lat, lng, radius_m):
precision = geohash_precision_for_radius(radius_m) -- 如 1km 用 6 字符
center_hash = geohash_encode(lat, lng, precision)
neighbor_hashes = geohash_neighbors(center_hash) -- 8 个相邻 cell
candidates = SELECT * FROM places
WHERE geohash LIKE ANY(center_hash, neighbor_hashes)
RETURN filter_by_haversine_distance(candidates, lat, lng, radius_m)邻居查询很关键:搜索半径能跨 geohash cell 边界,所以你必须总查中心 cell 加它的 8 个直接邻居,然后对候选应用精确的 Haversine 距离过滤。
Quadtree
Quadtree 递归把地图细分成四个象限,直到每个叶 cell 含少于一个阈值数量的对象(通常 50–100)。它对动态密度自适应索引理想:一个乡村县和市中心曼哈顿最终落在很不同的细分深度。Quadtree 用于驱动缩放级别感知渲染——低缩放时,一个节点代表整个区域;高缩放时它解析到单条道路或建筑。Quadtree 通常保在瓦片服务器内存里,并周期性从底层数据库重建。
Google S2 Geometry
S2 把球面映射到一个立方体的面,然后用希尔伯特曲线索引产生一个空间填充的 1D cell 层级。像 geohash,S2 cell 能存在任何有序键值存储里;不像 geohash,S2 cell 每级别面积更均匀且在极点正确工作。Google Maps 内部依赖 S2 做许多空间操作——若被问到,值得作为 geohash 的生产级替代提及。
第 6 步 — 地图瓦片渲染与投递
地图瓦片是平台的视觉层。一个瓦片(tile)是一个 256×256(retina 上 512×512)图像,代表特定缩放级别的固定地理边界框。slippy map XYZ 方案定义瓦片坐标:缩放级别 z、列 x、行 y——使每个瓦片 URL 全球唯一且确定,这是支持激进 CDN 缓存的关键属性。
瓦片生成管道
- 矢量数据——瓦片生成器从地图数据库读道路、边界和 POI 数据,用渲染引擎(Mapnik 或等价)渲染成栅格图像,并把结果存进分布式对象存储(GCS/S3)。
- 缩放级别策略——完整瓦片金字塔有 ~4.5 万亿瓦片。只有缩放级别 0–14(全球到街块)完全预渲染;缩放级别 15–22(建筑级)按需渲染并激进缓存。
- 差异重渲染——地图数据变化(新路、改名街道)时,CDC 事件通过计算哪些 XYZ cell 与被修改地理区域相交来触发只对受影响瓦片的重渲染。批量全球重渲染作为批作业周期运行。
- CDN 分发——预渲染瓦片被推到地理上靠近用户的 CDN 边缘节点。从 CDN 边缘服务的瓦片花 <5 ms;命中源对象存储的缓存未命中花 ~50 ms。热门缩放级别的缓存命中率超过 99%。
服务预渲染栅格瓦片是地图系统里杠杆最高的缓存决策。市中心曼哈顿的一个瓦片每天被请求数百万次——渲染一次、处处缓存。矢量瓦片流式(发原始地理数据做客户端渲染)减少带宽并支持动态样式,但代价是客户端计算和降低的可缓存性。Google Maps 用混合:高缩放级别(街道细节)用矢量瓦片、低缩放用栅格。
第 7 步 — 路由算法深入
标准图遍历(BFS)对路由不工作,因为道路段有可变权重(距离、限速、交通)。单源最短路径的正确算法是 Dijkstra(或带启发式更快收敛的 A*)。然而,查询时跨完整全球路网跑 Dijkstra 有 O((V+E)logV) 时间复杂度——对数十亿并发用户太昂贵。生产答案是一个分层预计算策略。
算法对比
| 算法 | 复杂度 | 用例 | 结论 |
|---|---|---|---|
| BFS | O(V+E) | 无权图 | 错——忽略道路权重 |
| Dijkstra | O((V+E)logV) | 单源最短路径 | 正确但全球规模太慢 |
| A* | O((V+E)logV) 最佳情况更快 | 启发式引导的单对 | 本地路由好,非全球 |
| Floyd-Warshall | O(V³) | 全对最短路径 | 仅小子图的离线预计算 |
| Contraction Hierarchies | O(V log V) 预处理;O(√V) 查询 | 路网 | 生产选择——比 Dijkstra 快 1000× |
Contraction Hierarchies (CH)
Contraction Hierarchies 是生产地图路由的主导算法。核心想法:离线给每个节点分配一个重要性排名(基于边差、所需 shortcut 数和道路等级),然后迭代"收缩"最不重要的节点,把它们的关联边对替换为保留最短路径距离的直接 shortcut 边。预处理产生一个高速节点有最高排名的分层图。
查询时,双向 Dijkstra 同时从源和目的运行,但每个搜索只松弛在层级里向上的边——完全跳过低重要性节点。这个修剪把搜索空间从数百万节点减到数千,在大陆级路网上交付 10 ms 内的查询时间。
-- CH 双向查询(简化)
FUNCTION ch_route(source, target):
forward_dist = {source: 0, 其他全部: ∞}
backward_dist = {target: 0, 其他全部: ∞}
forward_pq = MinHeap([(0, source)])
backward_pq = MinHeap([(0, target)])
best = ∞
WHILE 任一队列非空:
-- 从试探距离较小的方向扩展
IF forward_pq.min() <= backward_pq.min():
(d, u) = forward_pq.pop()
FOR edge (u → v) WHERE rank(v) > rank(u): -- 仅向上
IF forward_dist[u] + w(u,v) < forward_dist[v]:
forward_dist[v] = forward_dist[u] + w(u,v)
forward_pq.push((forward_dist[v], v))
best = min(best, forward_dist[v] + backward_dist[v])
ELSE:
-- 对称向后扩展
...
RETURN best预计算策略
除 CH 外,系统也在地理层面用存储换速度:采样的 section 边界节点(想:高速 section 的上下匝道,或城区的街区入口点)间的路线被完全预计算并存在键值路由存储里。导航随后解析为跨 section 的表查找,而非对大部分路线的实时图遍历。只有第一和最后的微段(街区级)需要实时 Dijkstra/A*。
当一个交通事件造成显著 ETA 变化,影响递归地向上冒泡穿过 section 层级,只更新受影响的路线段而非全局重算。本地路上的一个变化更新那条路的 section 缓存;只有 section 的最佳路径改变时更新才传播到下一 section 层。
第 8 步 — 实时导航
导航会话需要服务器和客户端间双向、低延迟通信——WebSocket 是这里正确的协议。一个 WebSocket Manager 维护已连接用户到其 WebSocket 服务器和端口的键值映射,使导航跟踪服务能触达任何活跃会话,无论哪个 WebSocket 服务器托管它。
三个事件触发导航更新:
- 路线偏离——用户偏离计划路径;用预计算路线缓存从新位置重算。
- 显著 ETA 延迟——路线上一个新事件超过阈值(如 +5 分钟);通知用户并提供备选。
- 更好路线可用——若更快路径打开(如平行高速交通疏通)主动重路由。
用户开始导航
→ 导航服务分配 route_id,打开 WS 连接
→ WebSocket Manager 记录: user_id → ws_server:port
每 5 秒:
客户端发: { user_id, lat, lng, speed, heading }
→ 位置队列(Kafka,至多一次)
├── 交通聚合器: 更新道路段权重
└── 导航跟踪器: 检测偏离 / ETA 变化
检测到偏离时:
导航跟踪器 → 路由服务(从新位置 CH 查询)
→ 结果经 WebSocket Manager 推回 → 客户端 WS
{ type: "reroute", new_polyline, new_eta_s }第 9 步 — 用户位置跟踪
活跃用户每 5 秒传输他们的 GPS 位置(启用位置共享时)。这些包流入一个把生产者与消费者解耦的 Kafka 消息队列。投递保证是至多一次:单个丢失的位置包可接受,因为下一个 5 秒后到达,且保证投递的成本(重传、ACK、去重)对此用例远超好处。
位置流并行服务多个下游消费者:
- 交通聚合器——跨道路段聚合速度读数以计算实时行驶时间;反馈进路由查询用的边权存储。
- 导航跟踪器——每用户会话状态;检测偏离并触发重路由。
- 分析服务——ETA 精炼、道路发现和热点预测的批处理。
- 打车 / 第三方 API 消费者——订阅匿名化、聚合交通数据的外部伙伴。
交通数据融合
原始 GPS ping 有噪声且稀疏。交通聚合器应用一个地图匹配(map-matching)步骤:用隐马尔可夫模型把原始 GPS 坐标投影到最可能的道路段(GPS 读数是真实路网位置的"噪声观测")。匹配的读数随后按道路段在 5 分钟窗口上平均以产生可靠的当前行驶时间。这些平均被写回 edges 表的 current_weight 字段,Contraction Hierarchy 查询引擎在查询时读它。
第 10 步 — 搜索与发现
地点名搜索由一个支持模糊匹配和 type-ahead 的 Elasticsearch 集群驱动。索引从两个流填充:直接地点名数据和地图 CDC 事件。地图浏览以适应缩放级别的优先级过滤显示节点——缩小只显主要地标;放大揭示细粒度细节。
地理编码管道
地理编码(地址字符串 → lat/lng)是一个多阶段 NLP 管道:
- 解析——把地址分词成组件(门牌号、街道、城市、邮编、国家)。
- 规范化——"St." → "Street"、"Ave" → "Avenue";处理缩写和国际格式。
- 候选检索——用模糊匹配查 Elasticsearch 匹配街道 + 城市组合以处理错别字。
- 排序——按匹配质量、热度(这个地址被查多频繁)和地理上下文(偏好靠近用户当前位置的结果)给候选评分。
- 插值——沿匹配街道段线性插值导出门牌号位置。
反向地理编码(lat/lng → 地址)反向跑管道:用 geohash 查找找最近道路段,然后经插值确定最近地址。
第 11 步 — 扩展:缓存、分片与 CDN
瓦片缓存
地图瓦片是系统里最可缓存的对象。缓存层级从客户端向外工作:
- 浏览器缓存——瓦片图像以长 Cache-Control max-age(7 天)缓存;返回访问时 ~80% 瓦片请求从浏览器缓存服务。
- CDN 边缘——地理分布节点;给定 XYZ 三元组的瓦片对所有用户相同,所以热门缩放级别 CDN 命中率超 99%。
- 源对象存储——GCS/S3 服务剩余缓存未命中;预渲染瓦片组织在匹配 XYZ 瓦片方案的桶层级里。
路由缓存
预计算的 section 到 section 路线结果存在分布式键值存储(Redis 集群或 BigTable),按 (section_node_a, section_node_b, mode) 为键。从旧金山到洛杉矶的路线请求解析为少数 section 查找而非实时 CH 查询。当交通数据使给定 section 对的最短路径成本变化超过阈值,缓存失效。
数据库分片
- 节点/边图——按地理区域(大洲 → 国家 → 州)分区。大多数路由查询是区域性的,所以区内查找留在一个分片。跨区路线在 section 边界 join。
- 地点数据——按 geohash 前缀分片,使"附近搜索"查询落在单个分片或一小组相邻分片。
- 位置 ping 流——Kafka 按 geohash cell 分区,使附近道路段的 ping 在同一分区以高效聚合。
第 12 步 — 容错
- 路由回退——若预计算路线缓存不可用,回退到对内存图的实时 CH 查询;若那超时,回退到缓存的"最后已知好"路线。当陈旧路线好过没有时,绝不返回错误。
- CDN 多源——瓦片 CDN 配两个不同区域的源对象存储桶;若主源不可达,CDN 自动故障转移到次源。
- 导航会话连续性——WebSocket Manager 状态带复制存在 Redis;若一个 WebSocket 服务器崩溃,重连的客户端被分配到一个新服务器,它在 <1 秒内从 Redis 重新取它的会话状态。
- Kafka 复制——位置 ping 主题跨 3 个 broker 复制;消费者组用 offset 提交,使 broker 重启后没有 ping 被处理两次。
- 地图数据幂等——每个地图编辑携带一个全局唯一 edit_id;幂等写处理器确保重试的 CDC 事件(如消费者重启后)不会两次应用同一道路编辑。
第 13 步 — ML 与分析服务
分析服务消费位置和行为数据以驱动几个高级功能:
- ETA 精炼——路由的基础 ETA 从历史平均速度算出。ML 模型用实时交通速度、时段模式、天气和特定 O/D 对的历史行程时长百分位调整它。结果是一个概率分布(如"25 分钟 80% 置信、95 分位 32 分钟")而非点估计。
- 热点预测——用时间模式(周五傍晚桥头)和事件数据(演唱会结束时间)预测拥堵区;在拥堵成形前浮现备选路线。
- 道路发现——通过聚合用户行驶模式识别未映射的道路或路径变化。若许多用户走一条一致的图外路径,系统标记它供人工审查和潜在地图更新。
- 用户画像——驾驶习惯、典型速度模式、家/办公位置预测以主动行程规划。
- 数据源评分——用户提交事件 vs 第三方提供商 vs 传感器数据的可靠性加权。
关键取舍
| 决策 | 选择 | 接受的取舍 |
|---|---|---|
| 路线计算 | 预计算 + CH + 存储 | 大存储和预处理成本;路线在交通缓存刷新前略陈旧(~5 分钟) |
| 位置投递 | 至多一次(Kafka) | 单个丢失的 5 秒 ping 影响可忽略;省大量基础设施复杂度 |
| 空间索引 | Geohash(主)+ quadtree(渲染) | Geohash cell 边界边界情况需查 9 个邻居 cell;需小的后过滤 |
| 地图数据一致性 | CDC 最终一致 | 新路可能需 30–60 秒出现在搜索/路由;对地图数据可接受 |
| 瓦片策略 | 预渲染栅格瓦片 | 地图变化时重渲染成本;比矢量瓦片样式更不灵活 |
| 交通新鲜度 | 5 分钟聚合窗口 | 实时速度不如每秒准;防止边权上的写放大 |
地图系统生死取决于它们的空间索引和预计算策略。Geohash 把 2D 地理桥接到 1D 键值查找;Contraction Hierarchies 以离线预处理为代价使路由查询比 Dijkstra 快 1000×;预渲染瓦片使系统里最可缓存的对象近乎免费服务。其他一切——CDC 管道、WebSocket 导航、至多一次位置 ping、交通融合——都关于让这些预计算答案保持最新并快速交付。
为什么不为每个路线请求实时跑 Dijkstra?跨全球路网 O((V+E)logV) 在 3B 用户下不可行——用 Contraction Hierarchies 离线预处理一个层级,然后查询时双向 Dijkstra 只探索一小部分节点并在 <10 ms 返回。
为什么 geohash 胜过纯 quadtree?Geohash 把 2D 坐标编码成 1D 可排序字符串,在标准键值存储上支持高效范围查询而无需特殊空间索引支持。Quadtree 对缩放自适应渲染密度更好。
为什么位置 ping 用至多一次?单个丢失的 5 秒 GPS 包对导航质量影响可忽略;保证投递的开销(重试、ACK、去重)在 10M 写/秒远超好处。
交通变化时怎么处理陈旧路由?交通聚合器在 5 分钟窗口刷新道路段权重;当最短路径成本变化超过阈值时预计算 section 缓存失效,只为受影响 section 对触发定向重算。
地图瓦片怎么保持快?XYZ slippy map 方案使每个瓦片 URL 确定,使热门缩放级别近 100% CDN 命中率。只有缓存未命中碰源对象存储。