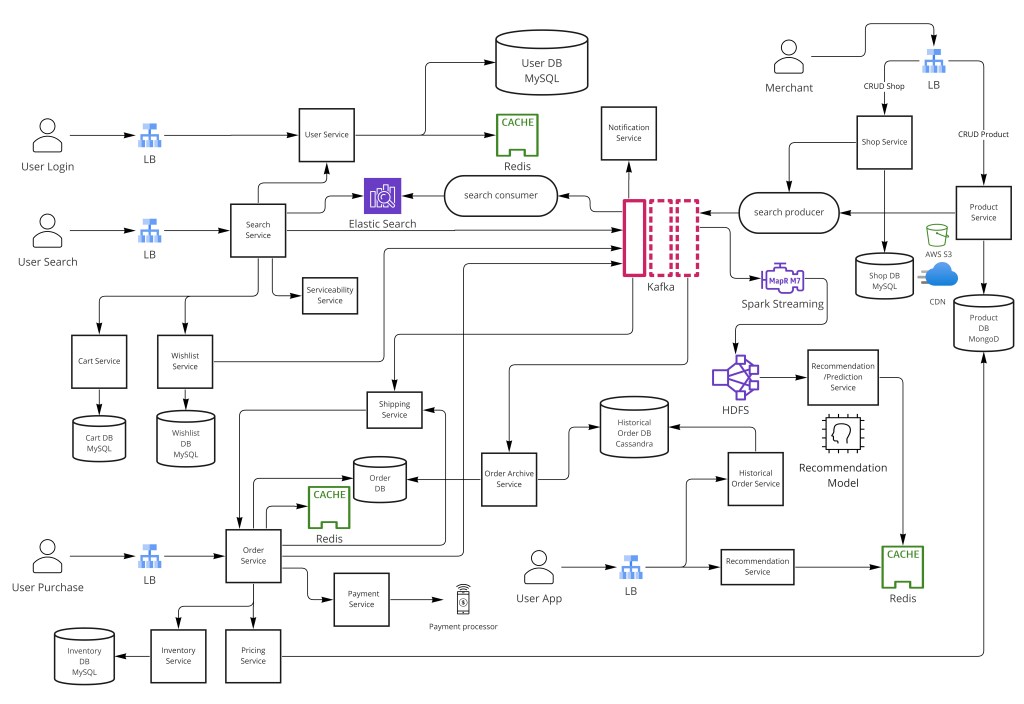
An e-commerce platform — think Amazon, Alibaba, Walmart, or Shopify — is one of the most demanding distributed systems you can be asked to design in an interview. It simultaneously combines real-time inventory management, financial transaction processing, high-traffic search and discovery, and ML-driven personalization, all under strict correctness requirements where an oversold item or a lost order translates directly into lost revenue and broken user trust. This guide walks the full interview arc: requirements, capacity estimation, API and data modeling, the high-level architecture, then a deep dive into the genuinely hard parts — checkout, inventory, payments, search, scaling, and fault tolerance.
- Microservices + API gateway — each service owns its data store; no cross-service direct DB access.
- SQL for money, NoSQL for catalogs — ACID for orders/users; document store for heterogeneous product schemas.
- Redis cart hold (TTL ~10 min) — soft-reserves inventory without permanently blocking stock; auto-released on expiry.
- Kafka decouples checkout — user gets instant acknowledgement; inventory deduction, payment, and notifications happen async downstream.
- CDC → Elasticsearch — search index stays eventually consistent without coupling write latency to indexing.
- Cassandra for archival — horizontally scalable, high write throughput for historical order records.
- Idempotency everywhere — payment keys, dedup on event consumers, and the Saga pattern for cross-service consistency.
Use microservices behind an API gateway: SQL for orders and users (ACID), NoSQL for product catalogs (schema flexibility), Cassandra for historical order archival, Redis with TTL for cart holds, and Kafka to decouple the checkout pipeline from downstream processing. Elasticsearch powers search via CDC-fed indexing. Hold consistency where it matters (money, stock) and embrace eventual consistency everywhere else.
Step 1 — Clarify Requirements
Before drawing a single box, scope the problem out loud. Interviewers award points for narrowing an impossibly broad prompt into a concrete, defensible subset. E-commerce is huge, so state what you will and won't cover.
Functional requirements
- User registration, authentication, and profile management.
- Merchant onboarding: shop creation and product management (CRUD with media).
- Product search, browse, cart, and wishlist.
- Checkout and payment, producing a durable order.
- Personalized homepage feed and order history.
- Order lifecycle tracking (placed → paid → shipped → delivered).
Non-functional requirements
- Low latency — search and page loads under ~200 ms p99; checkout should feel instant.
- High availability — target 99.99%; downtime during peak sales (Prime Day, 11/11) is catastrophic.
- Strong correctness where it counts — inventory must never oversell; payments must never double-charge.
- Scalability — survive 10–100× traffic spikes during flash sales.
- Durability — an acknowledged order is never lost.
Explicitly name what is out of scope — recommendations ranking internals, fraud detection, the seller analytics suite — so you can spend your time on the core transactional path. Saying "I'll treat payment processing as an external provider via webhooks" is a scoping decision, not a gap.
Step 2 — Capacity Estimation
Back-of-the-envelope numbers justify your storage and scaling choices. Assume a large platform with 100M daily active users (DAU).
Traffic
- If each DAU performs ~10 read actions (browse/search) per day: 100M × 10 = 1B reads/day ≈ 11,500 reads/sec average, and with a 5× peak factor roughly ~58K reads/sec at peak.
- If 1% of DAU place an order daily: 1M orders/day ≈ ~12 writes/sec average, but flash sales can concentrate that into minutes — design for thousands of order writes/sec in bursts.
- The read:write ratio is roughly 100:1, which screams "cache aggressively and use read replicas."
Storage
- 500M products × ~2 KB metadata each ≈ 1 TB of catalog data (before media).
- Product images/video live in object storage (S3) behind a CDN — easily petabytes, kept out of the primary DB.
- Orders: 1M/day × 365 × ~1 KB ≈ ~365 GB/year of hot order data, growing linearly — the reason historical orders are archived to Cassandra.
You don't need exact numbers — you need the right order of magnitude and the conclusions they drive: a 100:1 read/write ratio → caching + replicas; petabyte media → object storage + CDN; linearly growing orders → an archival tier.
Step 3 — API Design
Expose a clean REST surface through the API gateway. A few representative endpoints:
# Catalog & search
GET /api/products?q=shoes&category=men&page=2
GET /api/products/{productId}
# Cart (soft-reserves inventory)
POST /api/cart/items { productId, qty }
DELETE /api/cart/items/{id}
# Checkout — idempotent via client-supplied key
POST /api/orders
Idempotency-Key: "a1b2-c3d4"
{ cartId, addressId, paymentMethodId }
GET /api/orders/{orderId}Two details that earn credit: the checkout endpoint carries an Idempotency-Key so a retried request (flaky mobile network, double-tap) never creates a duplicate order; and search supports cursor/offset pagination because no client should ever fetch an unbounded result set.
Step 4 — Core Services
The platform is decomposed into focused microservices, each owning its data store. Services communicate over the API gateway synchronously for reads and over Kafka asynchronously for state changes — never by reaching into another service's database.
- User Service — authentication (OAuth2/JWT), profiles, addresses.
- Shop Service — merchant store creation and settings.
- Product Service — catalog CRUD, attributes, media references.
- Search Service — Elasticsearch-powered full-text and faceted search.
- Serviceability Service — filters products by purchase eligibility (region, legality, availability).
- Cart Service — Redis-backed carts with TTL inventory holds.
- Inventory Service — authoritative stock counts and reservations.
- Pricing Service — dynamic pricing, promotions, coupons.
- Order Service — order lifecycle state machine, the transactional source of truth.
- Payment Service — wraps external gateways (Stripe/PayPal), handles idempotency and reconciliation.
- Recommendation Service — ML-driven personalized suggestions.
- Notification Service — email, SMS, push.
Step 5 — Data Storage Decisions
Storage selection is driven by each service's access pattern and consistency needs. There is no single database that fits every workload — polyglot persistence is the point.
| Data Type | Storage | Rationale |
|---|---|---|
| Users, orders, shops | SQL (RDBMS) | ACID required for financial transactions and structured relational data |
| Product catalogs | NoSQL (Document) | Products have heterogeneous attribute sets; document stores avoid null-heavy schemas |
| Historical orders | Cassandra | Horizontally scalable, high write throughput; suited to append-heavy archival |
| Cart holds | Redis (TTL) | ~10-min TTL temporarily reserves stock without permanently blocking it |
| Search index | Elasticsearch | Full-text search, fuzzy matching, faceted filtering at scale |
| Media | Object store + CDN | Petabyte-scale blobs served close to the user, kept out of the DB |
Why a document store for products
A laptop has CPU, RAM, and screen size; a T-shirt has size and color; a book has an ISBN and page count. Modeling this in a single relational table produces either a forest of nullable columns or a clumsy entity-attribute-value schema. A document store (MongoDB, DynamoDB) lets each product carry exactly the attributes it needs, and the catalog is overwhelmingly read-heavy with no cross-row transactions — a perfect NoSQL fit.
Step 6 — Data Model
The order and inventory tables live in SQL because they demand transactions. A simplified schema:
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
status VARCHAR(20), -- PENDING|PAID|SHIPPED|...
total_cents BIGINT NOT NULL,
idempotency_key VARCHAR(64) UNIQUE,
created_at TIMESTAMP,
updated_at TIMESTAMP
);
CREATE TABLE inventory (
product_id BIGINT PRIMARY KEY,
available INT NOT NULL, -- on-hand minus reserved
reserved INT NOT NULL,
version INT NOT NULL -- optimistic lock
);The idempotency_key UNIQUE constraint is what makes a retried checkout safe at the database level: the second insert simply fails the uniqueness check, and the service returns the already-created order. The version column on inventory enables optimistic concurrency control, covered below.
Step 7 — The Checkout Pipeline
Checkout is the most critical — and most complex — flow. The key design insight is to decouple the user-facing confirmation from the downstream order-processing chain using Kafka. The user gets an immediate acknowledgement; inventory deduction, the payment charge, notification dispatch, and fulfillment kickoff happen asynchronously.
User clicks "Buy"
→ Cart Service validates the TTL hold is still active
→ Order Service writes a PENDING order to SQL (idempotency key)
→ Publishes OrderCreated to Kafka
├── Inventory Service: convert hold → permanent deduction
├── Payment Service (Stripe/PayPal): charge the card
│ └── webhook callback flips order PAID / FAILED
├── Notification Service: send confirmation
└── Recommendation Service: record purchase signalCross-service consistency: the Saga pattern
A single checkout touches the order, inventory, and payment services — three databases, no distributed transaction. The standard answer is a Saga: a sequence of local transactions, each publishing an event that triggers the next, with compensating actions on failure. If the payment is declined after stock was deducted, a PaymentFailed event drives the Inventory Service to release the reservation and the Order Service to mark the order CANCELLED. This trades atomicity for availability and eventual consistency — the right call for a system that must stay up during peaks.
Two-phase commit gives you atomicity but holds locks across services for the duration of the transaction, creating a coordinator bottleneck and cratering availability under load. Sagas keep each service independent and highly available at the cost of writing explicit compensation logic.
The order state machine
An order is best modeled as an explicit state machine; doing so prevents illegal transitions such as shipping an unpaid order or refunding twice. Each transition is triggered by an event and is idempotent, so replaying a Kafka message never advances the state incorrectly.
PENDING ──paid──▶ PAID ──pack──▶ PACKED ──ship──▶ SHIPPED ──▶ DELIVERED
│ │
└─timeout/fail─▶ CANCELLED └─return──▶ REFUNDED (terminal)Persist status in SQL guarded by an application-level check (or a DB CHECK/trigger) so that only a PAID order can move to PACKED, and CANCELLED/REFUNDED are terminal. The state field plus the updated_at timestamp also gives support and analytics a clean audit trail of every order's journey.
Step 8 — Inventory & the Oversell Problem
The hardest correctness problem in e-commerce is the cart-to-purchase gap. Deduct stock when an item is added to the cart and you block sales for users who abandon carts; deduct only at checkout and you risk overselling during high-demand bursts. The chosen middle ground is a Redis hold with a TTL (~10 minutes): inventory is soft-reserved on cart add and permanently deducted on successful checkout, while expired holds are released automatically.
Preventing concurrent oversell
When 10,000 buyers race for 100 units, two writes must never both succeed past zero. Two mechanisms:
- Optimistic locking — read the row with its
version, thenUPDATE ... WHERE version = :v; if zero rows update, someone else won — retry. Great when contention is usually low. - Atomic decrement — a Redis
DECR(or a conditional SQLUPDATE ... WHERE available > 0) makes the check-and-decrement a single atomic step. Best for extreme single-item contention like a flash drop.
-- atomic, safe under concurrency: only succeeds if stock remains
UPDATE inventory
SET available = available - 1, reserved = reserved + 1
WHERE product_id = 42 AND available > 0;
-- rows affected = 0 → sold out, reject the add-to-cartStep 9 — Payment Processing
Treat the card network as an external provider (Stripe, PayPal, Adyen) — you almost never want to be PCI-DSS Level 1 on your own. The Payment Service is a thin, careful wrapper around it:
- Idempotency keys — pass a unique key per charge attempt so a retry after a timeout never double-charges; the provider deduplicates.
- Webhooks drive state — never assume success from the synchronous response; the authoritative
charge.succeeded/charge.failedwebhook flips the order's status. Verify the webhook signature. - Reconciliation — a nightly job compares your orders against the provider's settlement report to catch dropped webhooks and stuck PENDING orders.
What if the charge succeeds but the webhook is lost? The order is stuck PENDING with the customer's money taken. Reconciliation plus a "query charge status" fallback after a timeout is the safety net — this is exactly the kind of failure mode interviewers probe.
Step 10 — Search and Discovery
Product and shop updates flow into the Elasticsearch cluster via Change Data Capture (CDC): the primary databases emit change events that a CDC connector (e.g., Debezium) publishes to Kafka, which feeds the search indexer. This keeps the index eventually consistent without coupling write latency to indexing — and avoids the dual-write trap.
The Search Service handles fuzzy matching, synonyms, and type-ahead. The Serviceability Service then filters results by the requesting user's region and purchase eligibility before they're returned. Ranking blends text relevance with business signals (popularity, conversion rate, margin).
A dual-write (app writes to both DB and Elasticsearch) diverges the moment one write fails — now your search shows products that don't exist or hides ones that do. CDC makes the database the single source of truth and the index a downstream, replayable projection of its change log.
Step 11 — Scaling for Peak Traffic
Flash sales and seasonal peaks (11/11, Black Friday) can spike traffic by orders of magnitude. The defenses, layer by layer:
- CDN + edge caching — static assets and even cacheable product pages served close to the user.
- Multi-layer caching — Redis in front of the catalog and hot product reads; cache-aside with sensible TTLs. A 100:1 read ratio means cache hits carry most traffic.
- Read replicas — fan reads out across replicas; keep writes on the primary.
- Database sharding — partition orders by
user_idand the catalog byproduct_idso no single node is a bottleneck. - Kafka as a shock absorber — the async pipeline buffers checkout bursts so the order back-end drains at its own pace instead of toppling.
- Rate limiting & load shedding — protect the platform from both abusive clients and genuine stampedes; queue users into a virtual waiting room for limited-stock drops.
- Autoscaling — stateless services scale horizontally on CPU/latency triggers.
Merchant processing models
- Large enterprises (batch pull) — Apache Airflow schedules bulk inventory/catalog pulls; better for high-volume scheduled updates.
- SMEs (push model) — changes are pushed immediately on product or order events for freshness.
Caching strategy in depth
With a 100:1 read/write ratio, caching is the single highest-leverage optimization. The default pattern is cache-aside: the app checks Redis first, falls back to the database on a miss, and populates the cache. The hard parts are not the happy path but the failure modes:
- Invalidation — on a product or price update, publish an event that evicts or refreshes the cached entry. A stale price shown at checkout is a real revenue and even legal risk, so price is cached with a short TTL and invalidated eagerly.
- Cache stampede — when a hot key expires, thousands of requests miss simultaneously and hammer the database. Mitigate with randomized TTL jitter, a single-flight mutex so only one request rebuilds the entry, or background refresh-ahead before expiry.
- Hot keys — a viral product can saturate one Redis shard. Replicate hot keys across shards or add a small in-process cache in front of Redis to absorb the spike.
- What to cache — product detail pages, category listings, and search results (short TTL); never the authoritative inventory count or order status, which must always be read strongly.
Sharding strategy in depth
A single primary cannot hold 500M products or absorb peak order writes, so partition horizontally — and choosing the shard key well is the whole game:
- Orders — shard by
user_idso a user's full history lives on one shard and the common "my orders" read stays single-shard. Sharding byorder_idwould scatter a user's orders across nodes. - Catalog — shard by a hash of
product_idfor even distribution and no hot partition. - Cross-shard queries — "all orders in a region this month" must fan out to every shard and merge, which is slow; route such analytical queries to an OLAP/warehouse copy instead of the OLTP path.
- Resharding — use consistent hashing or a lookup/directory service so adding capacity moves minimal data. Naive modulo sharding reshuffles almost every row when the shard count changes.
Step 12 — Reliability & Fault Tolerance
At 99.99% availability every dependency will eventually fail; the design must degrade gracefully rather than collapse.
- Replication + multi-AZ — every datastore runs with replicas across availability zones; automatic failover on primary loss.
- Circuit breakers — when the Recommendation Service is down, the homepage falls back to a non-personalized "popular items" feed instead of erroring.
- Idempotent consumers — Kafka guarantees at-least-once delivery, so every consumer dedups on event ID; re-processing an
OrderCreatedmust not deduct stock twice. - Dead-letter queues — events that repeatedly fail are parked for inspection instead of blocking the partition.
- Graceful degradation — search down? serve cached category pages. Pricing down? serve last-known price. Keep the buy button alive.
Observability
You cannot operate at 99.99% without seeing inside the system. Lean on the three pillars:
- Metrics — RED (Rate, Errors, Duration) per service plus business metrics (orders/min, payment success rate, cart-abandonment) in Prometheus/Grafana, with dashboards per service.
- Distributed tracing — a trace ID propagated across gateway → order → inventory → payment turns a "checkout is slow" report into an exact span you can point at.
- Structured logs & alerting — centralized logs keyed by
orderId/userIdfor grep-ability, and alerts on SLO burn (e.g., payment success rate < 99%, p99 latency > 300 ms) rather than on raw resource usage.
Security, Fraud & Abuse
Money attracts attackers, so defenses must layer across the stack rather than sit at a single gate:
- AuthN / AuthZ — OAuth2 with short-lived JWT access tokens plus refresh tokens; merchant and admin APIs carry separate scopes so a leaked customer token can't touch the catalog.
- Rate limiting — per-user and per-IP token buckets at the gateway blunt credential stuffing, scraping, and accidental client retry storms.
- Fraud scoring — velocity checks (many orders or many cards in a short window), device fingerprinting, and an ML risk score route suspicious orders to a hold/review queue before fulfillment.
- Bot defense for drops — limited-stock flash sales attract bots; combine CAPTCHAs, a virtual waiting room, and per-account purchase limits.
- PCI scope minimization — never store raw card data; tokenize through the payment provider so a breach can't leak card numbers.
Returns, Refunds & Multi-Region
The post-purchase flow is often skipped in interviews but is genuine scope. A return spawns a reverse-logistics task; on receipt of the item, a refund re-enters the Payment Service (again idempotent, again webhook-confirmed) and restocks inventory. Refunds are their own small state machine and must reconcile against the provider's settlement report just like charges.
For a global audience, a multi-region deployment cuts latency and provides disaster recovery. Catalog and search replicate read-only into every region, while orders are typically pinned to the user's home region to keep the transactional path simple, with asynchronous cross-region replication for DR. Strong global consistency is expensive and rarely worth it — most designs accept regional ownership plus eventual global replication, failing over to another region only on a regional outage.
Step 13 — ML and Recommendations
User behavior signals — search queries, cart additions, wishlist saves, and completed purchases — are captured via Kafka and fed into Spark Streaming for near-real-time analysis. The Recommendation Service uses them for:
- User segmentation (regression models, KNN clustering).
- Personalized homepage and "customers also bought" modules.
- Dynamic pricing and promotion targeting.
- Demand forecasting that feeds inventory planning.
Every table carries created_at / updated_at columns that pull double duty: debugging production issues and providing temporal features for these models.
Key Tradeoffs
| Decision | Choice | Trade-off accepted |
|---|---|---|
| Order consistency | Strong (SQL + ACID) | Lower write throughput than NoSQL, mitigated by sharding |
| Catalog & search | Eventual (CDC) | A new product may take seconds to appear in search |
| Cross-service txn | Saga | Must write explicit compensation logic; no global rollback |
| Inventory hold | Redis TTL | Tiny window where a held-then-abandoned item is briefly unavailable |
| Checkout path | Async via Kafka | Order is "placed" before payment confirms; status updates a beat later |
E-commerce system design is fundamentally about isolating consistency domains: SQL + ACID for money and orders, document stores for flexible catalogs, Cassandra for archival scale, and Kafka to decouple the checkout critical path from all downstream effects. The Redis TTL cart hold is the canonical answer to the oversell-vs-lost-sale tradeoff, and the Saga pattern is how you keep correctness without a distributed transaction.
How do you prevent overselling during flash sales? Redis TTL hold (~10 min) soft-reserves on cart add; permanent deduction only on confirmed checkout via an atomic conditional decrement; expired holds auto-release.
Why Kafka between checkout and payment? Decouples user-facing latency from downstream work — instant order confirmation while inventory, payment, and notifications proceed asynchronously, with Kafka also buffering bursts.
How do you keep three services consistent without 2PC? The Saga pattern — local transactions chained by events, with compensating actions (release stock, cancel order) on failure.
Why CDC into Elasticsearch instead of dual-writes? CDC keeps the index consistent with the DB as a replayable projection; dual-writes diverge if the index write fails.
How do you avoid double-charging a customer? Idempotency keys on the charge call plus webhook-driven status and nightly reconciliation.